在使用mongo副本集的时候就在想,这些副本不用来读太浪费了,再翻阅php的mongodb驱动,发现一个美好的readPreference,可以设定读取的优先级,其中就有优先读取副本,甚至还可以设定读取最小网络延迟的节点,具体可以参考:http://php.net/manual/zh/mongodb-driver-readpreference.construct.php
愿望是美好的,然而使用的过程中当我优先读取secondary时候,经常发现有的读取时间在几秒甚至几十秒的情况,也是醉了。于是经过一番搜索,发现有一个博客提到了这个问题,在官方文档中有说明,原文如下:
How does concurrency affect secondaries?
In replication, MongoDB does not apply writes serially to secondaries. Secondaries collect oplog entries in batches and then apply those batches in parallel. Secondaries do not allow reads while applying the write operations, and apply write operations in the order that they appear in the oplog.
地址是:https://docs.mongodb.com/manual/faq/concurrency/#how-does-concurrency-affect-secondaries
说的是在副本集中,mongodb在同步oplog的时候,副本是不能被读取的。我也是...呵呵哒....
对于频繁写入的mongo,直接读primary吧!
你可能还喜欢下面这些文章
读取文件,读取网页,file_get_contents总是首选。既简单,又高效。读取网页: $content = file_get_contents("http://imhuchao.com")这里要说的是file_get_contents的一些"高级"的用法,平时大概用不上。file_get_contents可以用来发送post请求,设定超时时间等等,不弱于curl。函数说明是这样子的string file_get_contents ( string $filename ]]] )其中第三个参数$context能够让file_get_content发送post请求,控制超时等功能先看一个简单
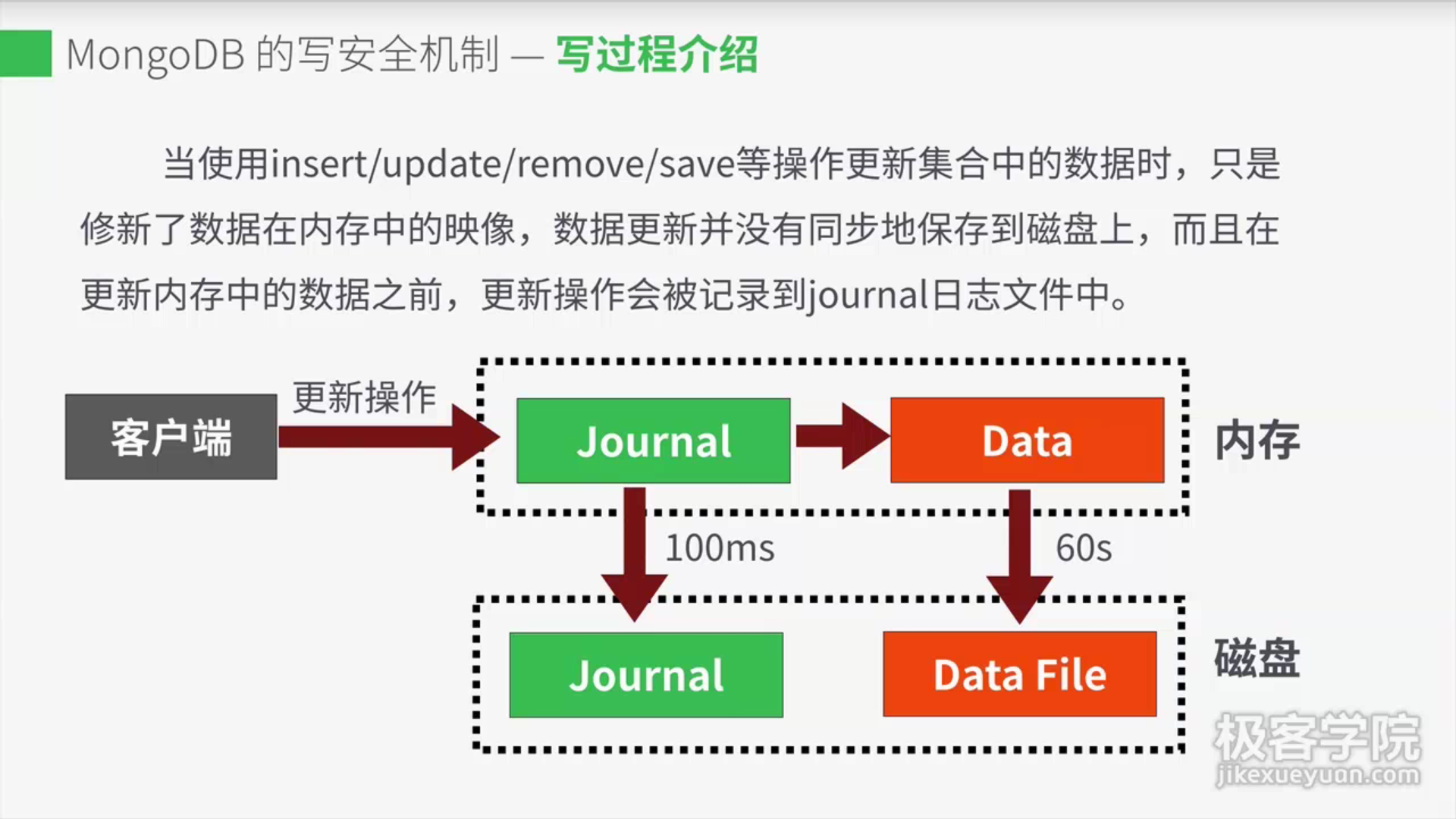
写入安全(Write Concern)是一种由客户端设置的,用于控制写入安全级别的机制,通过使用写入安全机制可以提高数据的可靠性。MongoDB提供四种写入级别,分别是: (Unacknowledged)非确认式写入 (Acknowledged)确认式写入 (Journaled)日志写入 (Replica Acknowledged)复制集确认式写入1. 非确认式写入2. 确认式写入 3. journal日志写入64位机器上,MongoDB 2.0以上版本默认情况下是开启journaljournal文件位于journal目录中,只能以追加方式添加数据,文件名以j._开头数据库正
在使用apidoc之前,我一直使用wiki来写文档,后来发现这种方式更新起来比较痛苦,时间一长甚至就忘记了更新了。一直在寻找能够使用注释直接生成文档的程序。某一天同事推荐了apidoc,发现这正是我想要的工具。apidoc原理apidoc的原理是扫描你的代码文件,提取出注释部分,根据一些规则生成相应的文档。默认的模板久很美观,十分适合作为api文档的生成器。目前apidoc支持的注释基本涵盖了大部分语言的风格了,c,java,php,js,python,perl,lua, Erlang...安装需要使用npm安装,如果没有安装npm,请先去https://www.npmjs.com/下载npm
树树是一种层次关系,在日常生活非常常见,比如社会关系,亲缘关系,文件管理。一棵树是一些节点的集合,这个集合可以是空集,若非空,则一棵树由称作为根的节点r以及0个或者多个非空的(子)树组成,这些子树中的每一棵都是被来自根r的一条有向的边所连接。一种数据结构需要包含一些操作,树这种数据结构有增加,删除,查找,修改。节点节点的度:节点子树的个数。叶子节点:没有儿子的节点,也就是度为0的节点。节点的层次:规定跟节点在1层,其他节点的层次为父节点的层次加1。节点的高:节点的高为从这个节点到叶子的最长路径,所有树叶的高都是0。节点的深度:从跟节点到该节点的唯一路径长,根的深度为0。节点定义typedef
从2011年开始,我便写博客了。今年,一个非常不幸的事情,我的博客被屏蔽了,那一刻的心情我无法形容,但又无可奈何。于是我又注册了一个域名imhuchao.com,继续我的博客生活。程序员没有博客,那便如同剑客没有酒,那是何等的寂寥!经历了这些之后,我觉得我应该把博客记录下来。那么起点就设定在今天吧,原来的数据封存起来,不做开放,或许多年之后,我翻开来,轻叹一声,哦,那是2011年我写的东西,真快啊。好久了,应该快一年没有关注wordpress了,下载安装,再到访问后台,不到一分钟的时间。打开前台一看,哇,竟是如此的清新脱俗!从未想到她默认的主题变得如此的好看。四年时间,任何人也都能够成长,无论
在一个高并发,但是数据量不大的系统中,使用Redis做数据库再好不过,结合Swoole,只需要很少的机器就能抗住很大的量。Redis大多数的应用可能都是当做缓存,当作为一个数据库用的时候,就必须要考虑持久化的问题了。持久化的意思就是将内存中的数据写到磁盘中,当再次重启之后,数据可以从磁盘中进行恢复,不会丢失。Redis持久化有两个策略,一个是RDB快照,一个AOF日志,不管是什么策略,最终的目的都是将数据保存在磁盘上,并不高深。只需要耐心的看看这两种策略,就能明白了。RDB快照从名字上我们就能知道这是RedisDB的缩写了,Redis快照是这样生成的,到了需要生成快照的时候,通过fork当前进