写入安全(Write Concern)是一种由客户端设置的,用于控制写入安全级别的机制,通过使用写入安全机制可以提高数据的可靠性。
MongoDB提供四种写入级别,分别是:
- (Unacknowledged)非确认式写入
- (Acknowledged)确认式写入
- (Journaled)日志写入
- (Replica Acknowledged)复制集确认式写入
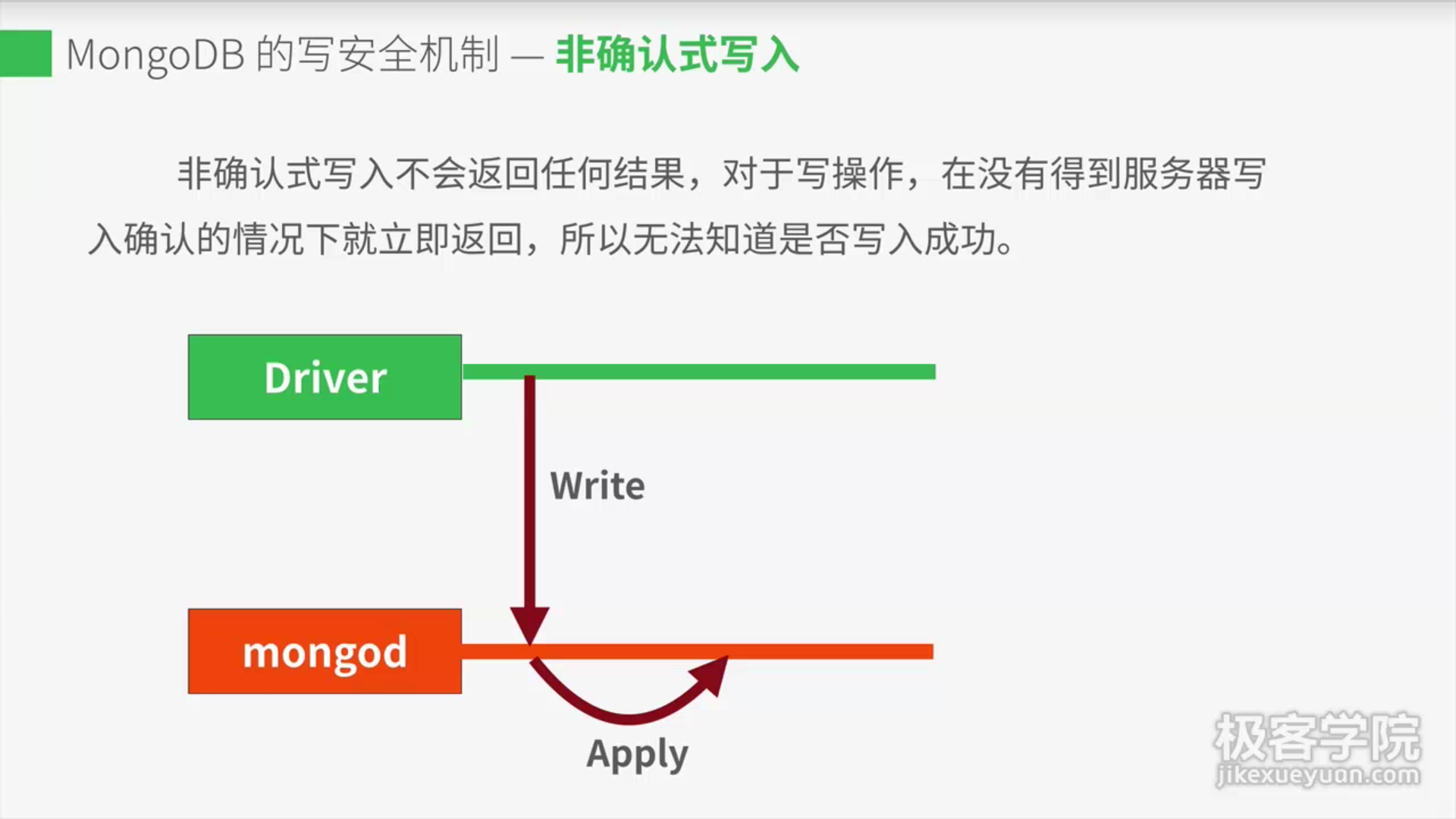
1. 非确认式写入
2. 确认式写入

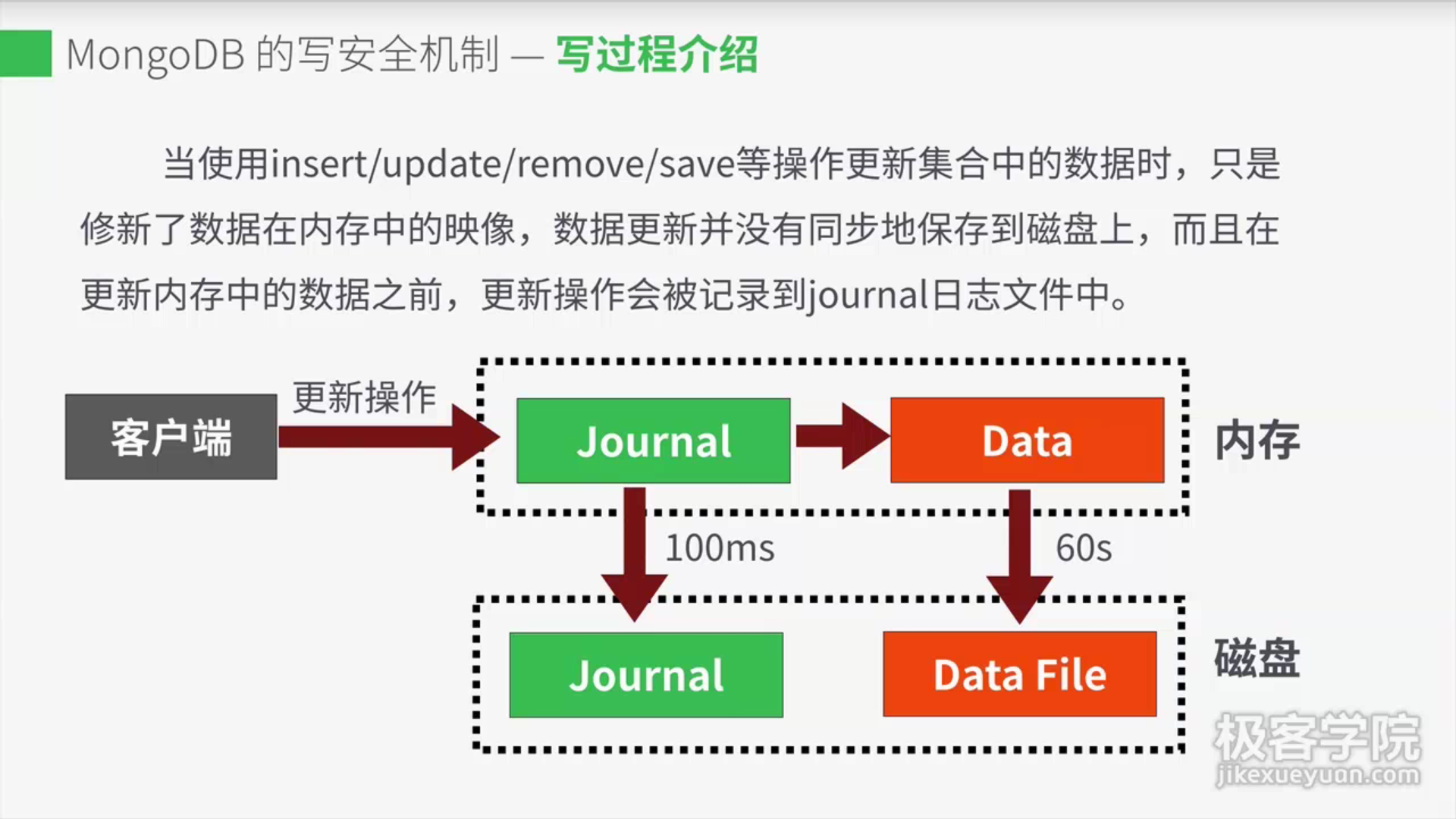
3. journal日志写入
64位机器上,MongoDB 2.0以上版本默认情况下是开启journal
journal文件位于journal目录中,只能以追加方式添加数据,文件名以j._开头
数据库正常关闭时(例如:db.shutdownServer()来关闭数据库),数据库服务会清空journal目录下的所有文件
MongoDB数据库每隔100ms或30ms向journal文件中flush一次数据
journal日志和data数据在一个磁盘上时每隔100ms刷新一次,不在一个磁盘上时30ms刷新一次,建议把journal日志和data数据放在不同的磁盘上,提高数据的可靠性

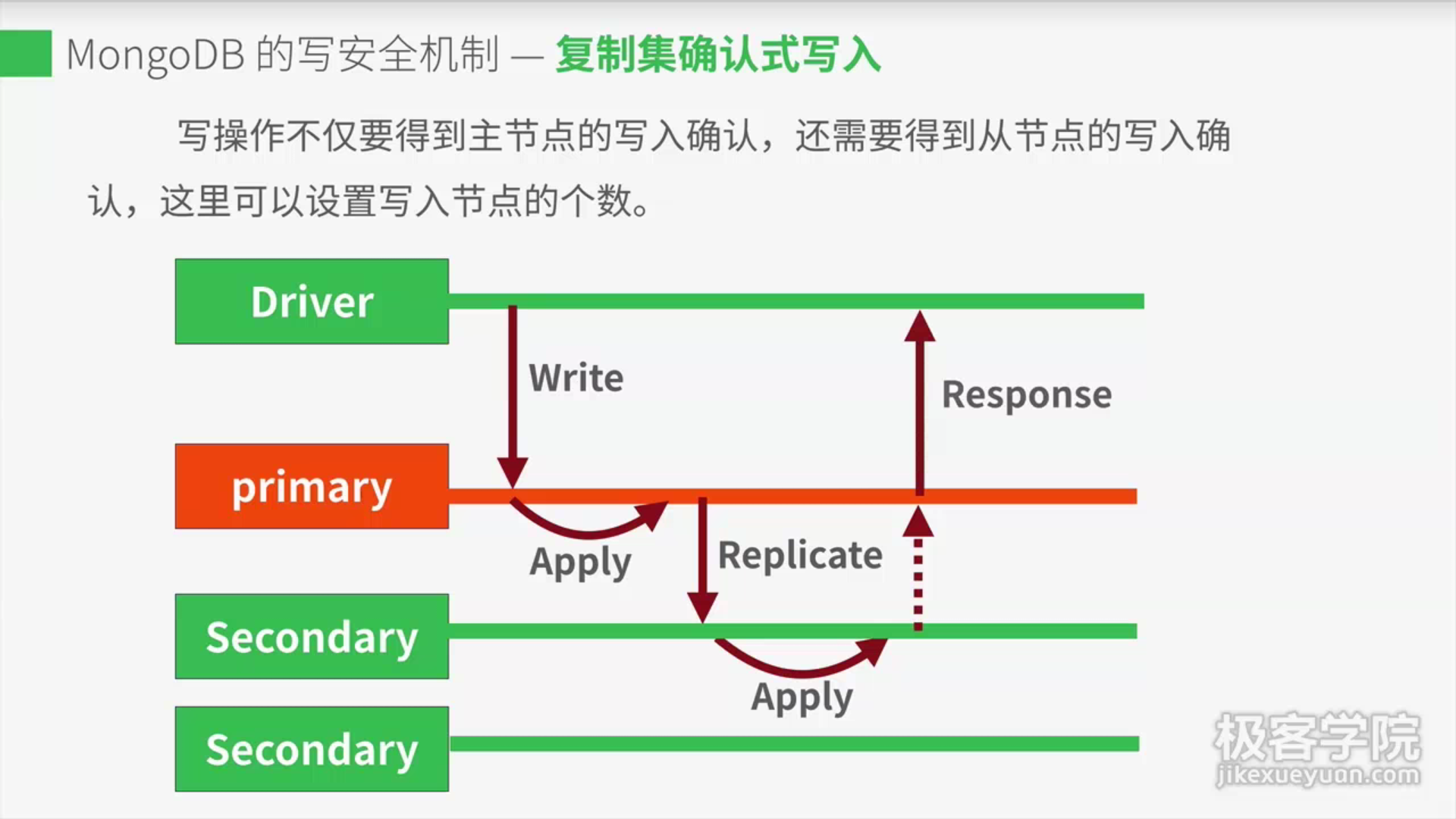
4. 复制集确认式写入
5.写入安全级别的使用

W选项
0:非确认式写入
1:确认式写入
说明:这个级别下,对副本级只对主库做确认写入
2:副本级确认式写入
说明:这个级别下,副本集第一个slave写入成功后就响应给client
majority:复制级更多slave写入成功后,在响应给client
你可能还喜欢下面这些文章
在一个高并发,但是数据量不大的系统中,使用Redis做数据库再好不过,结合Swoole,只需要很少的机器就能抗住很大的量。Redis大多数的应用可能都是当做缓存,当作为一个数据库用的时候,就必须要考虑持久化的问题了。持久化的意思就是将内存中的数据写到磁盘中,当再次重启之后,数据可以从磁盘中进行恢复,不会丢失。Redis持久化有两个策略,一个是RDB快照,一个AOF日志,不管是什么策略,最终的目的都是将数据保存在磁盘上,并不高深。只需要耐心的看看这两种策略,就能明白了。RDB快照从名字上我们就能知道这是RedisDB的缩写了,Redis快照是这样生成的,到了需要生成快照的时候,通过fork当前进
最近在写hadoop的streaming任务,在输出的时候用了std::endl,就像下面这样:运行后发现程序跑的比python还慢,令人费解。我入门C++的时候,输出hello world也是这样写的,有什么问题?于是查了一下std::endl,发现问题挺大。std::endl解释如下:也就是说每次执行到std::endl的时候都会将缓冲区的内容写入到输出的对象中,这样一来速度慢也就不足为奇。性能测试不加std::endl性能高出20倍。如果程序的逻辑十分简单,那么输出字符串的时候最好用"\n"代替加std::endl
mysql满查询有助于让我们发现系统中瓶颈所在。开启方法默认情况满查询应该关闭,如果需要分析则需要手动开启。mysql> show variables like '%slow_query_log%'; +---------------------+--------------------------------------+ | Variable_name | Value | +---------------------+--------------------------------------+ | slow_
从连接mongo开始,熟悉一下命令行下面的mongo使用连接普通连接mongo mongodb://ip:port查看数据库show dbs选择或者创建数据库use mydb创建一个集合比如创建一个mycollection的集合db.createCollection('mycollection')显示数据库中所有的集合show collections向集合中写入数据假设我们创建了一个mycollection集合,实际上当我们没有创建mycollection集合的时候,执行下面的命令mongo会自动创建一个mycollection集合db.mycollection.insert({"foo",'
nginx日志可以十分方便的看到每一个请求的响应速度,通常我会用awk去分析这些请求耗时。通常nginx的log配置是这样的log_format access_comment '$remote_addr - $remote_user "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" $http_x_forwarded_for ' '$upstream_response_time $request_time';我们记录的日志类似于这样127.0.0.1 - - "POST /get" "M
在使用mongo副本集的时候就在想,这些副本不用来读太浪费了,再翻阅php的mongodb驱动,发现一个美好的readPreference,可以设定读取的优先级,其中就有优先读取副本,甚至还可以设定读取最小网络延迟的节点,具体可以参考:http://php.net/manual/zh/mongodb-driver-readpreference.construct.php愿望是美好的,然而使用的过程中当我优先读取secondary时候,经常发现有的读取时间在几秒甚至几十秒的情况,也是醉了。于是经过一番搜索,发现有一个博客提到了这个问题,在官方文档中有说明,原文如下:How does concur
SQLAlchemy是python下十分流行的orm(对象关系映射)框架。官方的介绍是这样的:SQLAlchemy将数据库视为关系代数引擎,而不仅仅是表的集合。行不仅可以从表中选择,还可以选择连接其他的选择语句; 这些单元中的任一个可以组成更大的结构。SQLAlchemy的核心表达语言正是基于这个概念。SQLAlchemy以其对象关系映射器(ORM)而闻名,它提供一个数据映射器模式的可选组件,其中可以通过多种方式将类映射到数据库,实际上对象模型和数据库模式从一开始就可以完整分离。SQLAlchemy的对这些问题的总体思路来源于其它优秀的 SQL/ORM 工具,植根于所谓的完全不同complim
最近业务可能会用到mongodb,因此将mongodb的一些特性和常用命令整理一下。mongodb是一种非关系型数据库中最像关系数据库的,但我用mongodb仍然只把它当做KV存储,其他的关系一概不做,对于关系,还是让MySQL去做吧!关于mongo集群的搭建已经有运维帮我搭建好了,我就直接用了,但是在用之前,了解mongo集群的搭建十分有必要。关于Mongos,MongodMongos:起着路由的作用,根据分片key找到数据所存放的分片位置Mongod:数据存放的位置关于索引索引在任何数据库都起着至关重要的作用,没有索引的数据只能是一堆杂乱无章的集合,在mongo的集合中,可以创建索引,创建
原文标题:15天玩转redis —— 第十一篇 让你彻底了解RDB存储结构这里我们来继续分析一下RDB文件存储结构,首先大家都知道RDB文件是在redis的“快照”的模式下才会产生,那么如果我们理解了RDB文件的结构,是不是让我们对“快照”模式能做到一个心中有数呢?一:RDB结构剖析首先呢,我们要对RDB文件有一个概念性的认识,比如下面画的图一样: 从图中,我们大概看到了RDB文件的一个简要的存储模式,但为了更好的方便对照,我准备save一个empty database,对比一下看看效果: 然后我们用winHex打开dump.rdb文件,看看它的16进制。好了,该打开的我都
1、安装libevent官网:http://www.libevent.org/2、安装 BerkeleyDB官网:http://www.oracle.com/technetwork/products/berkeleydb/downloads/index.html(下载需要登录)安装:安装完成之后:或者:添加:并执行:3、安装 MemcacheQ官网:http://memcachedb.org/memcacheq/测试是否安装成功:4、启动服务建立相关目录:启动服务:参数说明:-d : 以后台服务方式运行-l : 设置监听地址及端口(默认是22201)-A : 数据页大小-H : 数据保存目录-
赞赏 微信赞赏
微信赞赏 支付宝赞赏
支付宝赞赏
