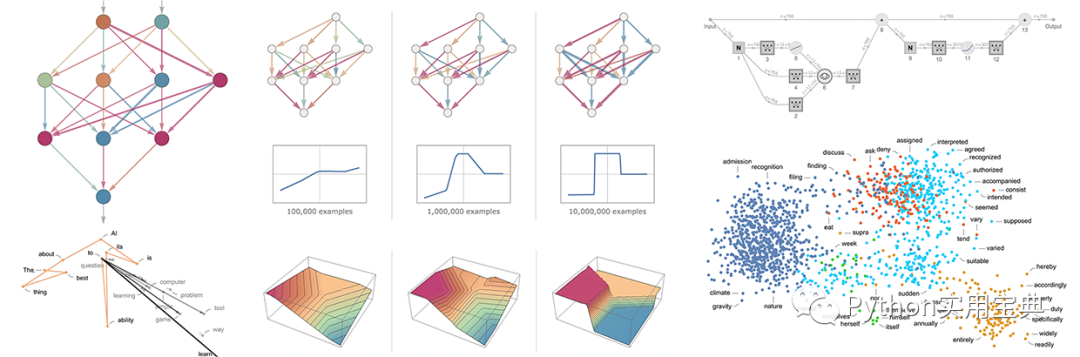
“万事万物都有一个模式,它是我们宇宙的一部分。它具有对称、简洁和优雅——这些品质你总能在真正的艺术家的作品中找到。你可以在季节的更替中、在沿着山脊的沙迹中、在杂酚油灌木的树枝丛中或其叶子的图案中找到它。
我们试图在我们的生活和社会中复制这些模式,寻找令人舒适的节奏、舞蹈和形式。然而,在寻找终极完美的过程中也可能会遇到危险。显然,最终的模式有其自身的固定性。在如此完美的情况下,一切事物都走向死亡。” ~ 沙丘 (1965)
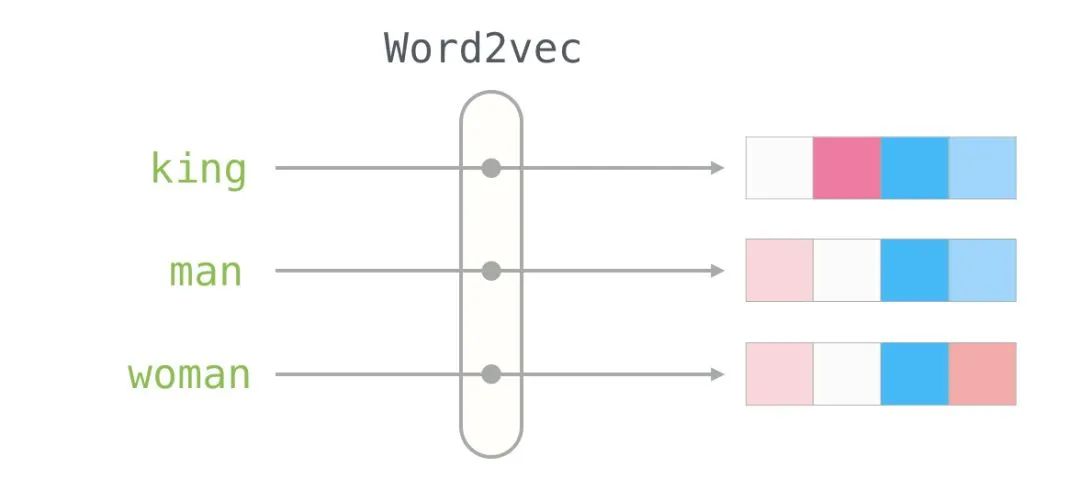
我发现Embedding(中文翻译为嵌入,但不好理解,因此后续直接使用原术语Emdedding表示)的概念是机器学习中最迷人的想法之一。如果您曾经使用过 Siri、Google Assistant、Alexa、Google Translate,甚至具有下一个单词预测功能的智能手机键盘,那么您应该能从这个已成为自然语言处理模型核心的想法中受益。
经过几十年发展,神经网络模型中的Embedding已经十分成熟(最近的发展的语境Emdedding,从而催生了BERT和 GPT等尖端模型)。
Word2vec是一种生成 Embedding 的方法,发布于2013 年。但除了作为生成embedding的方法之外,它的一些概念已经被证明可以有效地创建推荐引擎和理解时序数据。在商业、非语言任务中,像Airbnb、阿里巴巴、Spotify这样的公司都从NLP领域中提取灵感并用于产品中,从而为新型推荐引擎提供支持。
你可能还喜欢下面这些文章
上一篇预测股市涨跌的翻车了!毕竟概率在这儿,70%-80%的的概率毕竟不能保证一定是正确的。今天沪深300指数上午上涨,下午开始下跌,最终收跌-0.06%,感觉还好!今天晚上用之前训练好的模型去预测,结果看起来还比较乐观,如图:虽然模型也没能给出明确的涨还是跌,但看起来涨的概率还是比跌的概率稍微大一点点。此外,从我个人的主观感觉来看,明天沪深300上涨的概率也比较大,毕竟前值是下跌的趋势,而最近几天基本跌不下去了。模型说明简单说一下模型里面的数字都是什么意思吧。这些模型是根据过去2年的沪深300的波动特征训练得到的模型,上面的精准度代表预测正确的次数/总次数,比如model_6,精准度为0.7
在C++中,你可以使用的成员函数来获取最后一个元素。这个函数返回对向量中最后一个元素的引用。以下是一个简单的示例:在这个例子中,我们创建了一个包含五个整数的。然后,我们使用函数获取最后一个元素,并将其存储在变量中。最后,我们打印出这个元素。请注意,如果向量是空的(即,不包含任何元素),调用函数将导致未定义行为。因此,在调用之前,最好先检查向量是否为空,这可以通过调用成员函数来完成。
特征工程是数据分析中最耗时间和精力的一部分工作,它不像算法和模型那样是确定的步骤,更多是工程上的经验和权衡。因此没有统一的方法。这里只是对一些常用的方法做一个总结。本文关注于特征选择部分。后面还有两篇会关注于特征表达和特征预处理。1. 特征的来源在做数据分析的时候,特征的来源一般有两块,一块是业务已经整理好各种特征数据,我们需要去找出适合我们问题需要的特征;另一块是我们从业务特征中自己去寻找高级数据特征。我们就针对这两部分来分别讨论。2. 选择合适的特征我们首先看当业务已经整理好各种特征数据时,我们如何去找出适合我们问题需要的特征,此时特征数可能成百上千,哪些才是我们需要的呢?第一
从程序员的角度来看, Shell本身是一种用C语言编写的程序,从用户的角度来看,Shell是用户与Linux操作系统沟通的桥梁。用户既可以输入命令执行,又可以利用 Shell脚本编程,完成更加复杂的操作。在Linux GUI日益完善的今天,在系统管理等领域,Shell编程仍然起着不可忽视的作用。深入地了解和熟练地掌握Shell编程,是每一个Linux用户的必修 功课之一。Linux的Shell种类众多,常见的有:Bourne Shell(/usr/bin/sh或/bin/sh)、Bourne Again Shell(/bin/bash)、C Shell(/usr/bin/csh)、K Shel
这篇文章讨论基于语言的基本要素,如何快速入门一种计算机语言。是一篇语言从学习到使用的指导手册,并且这种学习方式是一个系统的学习,相比于碎片化的学习,这种学习更加不容易遗忘。语言的基本成分语言的基本成分为数据、运算、控制、传输。想想你学过的语言,是不是都是这样。归结语言的组成成分,学习一门语言可以从这四个方面下手,这四个方面掌握之后,对这个语言就有个最基本的了解了。语言基本成分:数据数据是程序操作的对象。实际上我们可以思考,一个数据拥有的属性有哪些,根据我们已经掌握的语言来说(比如PHP)。$a = 1$a是数据,那么这个数据有哪些属性呢?名称(a),类型(int)。从这一行代码只能发现这两个属
编译步骤gcc 与 g++ 分别是 gnu 的 c & c++ 编译器。gcc/g++ 在执行编译工作的时候,总共需要4步:预处理,生成 .i 的文件将预处理后的文件转换成汇编语言, 生成文件 .s 有汇编变为目标代码(机器代码)生成 .o 的文件连接目标代码, 生成可执行程序 参数详解-x language filename参数含义为指定文件所使用的语言。根据约定,C语言的后缀名称为".c",而 C++ 的后缀名为".cpp"或".cc",但如果你的源代码后缀不约定的那几种,那么需要使用-x参数来指定文件所使用的语言。这个参数对他后面的文件名都起作用。 可以使用的参数吗有下面的这些:
近来项目中使用websocket,于是来研究一番。websocket传输协议有两个部分,握手和数据传输握手GET / HTTP/1.1HOST: <IP>:<PORT> Sec-Websocket-Version: 13Sec-Websocket-Key: <KEY>Connection: keep-alive, UpgradeUpgrade: websocket之后服务端会返回类似下面的数据HTTP/1.1 101 Switching ProtocolsUpgrade: websocketConnection: UpgradeSec-WebSocket-A
程序员难免要经常画流程图,状态图,时序图等。以前经常用 visio 画,经常为矩形画多大,摆放在哪等问题费脑筋。有时候修改文字后,为了较好的显示效果不得不再去修改图形。今天介绍的工具是如何使用 Sublime + PlantUML 的插件画流程图,状态图,时序图等。这是一种程序员看了就会爱上的画图方式:自然,高效。什么是 PlantUMLPlantUML 是一个画图脚本语言,用它可以快速地画出:时序图流程图用例图状态图组件图简单地讲,我们使用 visio 画图时需要一个一个图去画,但使用 PlantUML 只需要用文字表达出图的内容,然后就可以直接生成图片。看一个最简单的例子:软件安装这些软件
在使用php的时候,我很少用到print这个函数,哦,不对,这是一个语言结构,而并非日函数!看一段代码
是一个JavaScript对象,它最初由微软设计,随后被 Mozilla、Apple和Google采纳。如今,该对象已经被 W3C组织标准化。通过它,你可以很容易的取回一个URL上的资源数据。尽管名字里有XML, 但 可以取回所有类型的数据资源,并不局限于XML。而且除了HTTP ,它还支持 和 协议。创建一个 实例, 可以使用如下语句:方法概述非标准方法属性AttributeTypeDescription一个JavaScript函数对象,当readyState属性改变时会调用它。回调函数会在user interface线程中调用。警告: 不能在本地代码中使用. 也不应该在同步模式的请求中