如果没有额外的设置,iterm2 使用 rzsz 的时候会卡在
waiting to receive.**B0100000023be50这个时候就需要使用iterm2提供的trigger来实现rzsz的功能。
第一步:本机安装rzsz
使用rzsz之前本地也需要安装
brew install lrzsz如果没有安装brew,请先安装brew,mac必备的包管理器!
第二步:创建发送和接收脚本
发送文件的脚本如下,可以复制下面的内容,保存在 /usr/local/bin/iterm2-send-zmodem.sh中。
#!/bin/bash
# Author: Matt Mastracci (matthew@mastracci.com)
# AppleScript from http://stackoverflow.com/questions/4309087/cancel-button-on-osascript-in-a-bash-script
# licensed under cc-wiki with attribution required
# Remainder of script public domain
osascript -e 'tell application "iTerm2" to version' > /dev/null 2>&1 && NAME=iTerm2 || NAME=iTerm
if [[ $NAME = "iTerm" ]]; then
FILE=`osascript -e 'tell application "iTerm" to activate' -e 'tell application "iTerm" to set thefile to choose file with prompt "Choose a file to send"' -e "do shell script (\"echo \"&(quoted form of POSIX path of thefile as Unicode text)&\"\")"`
else
FILE=`osascript -e 'tell application "iTerm2" to activate' -e 'tell application "iTerm2" to set thefile to choose file with prompt "Choose a file to send"' -e "do shell script (\"echo \"&(quoted form of POSIX path of thefile as Unicode text)&\"\")"`
fi
if [[ $FILE = "" ]]; then
echo Cancelled.
# Send ZModem cancel
echo -e \\x18\\x18\\x18\\x18\\x18
sleep 1
echo
echo \# Cancelled transfer
else
/usr/local/bin/sz "$FILE" -e -b
sleep 1
echo
echo \# Received $FILE
fivim /usr/local/bin/iterm2-send-zmodem.sh
chmod +x /usr/local/bin/iterm2-send-zmodem.sh接收文件的脚本如下,同样可以复制保存在/usr/local/bin/iterm2-recv-zmodem.sh
#!/bin/bash
# Author: Matt Mastracci (matthew@mastracci.com)
# AppleScript from http://stackoverflow.com/questions/4309087/cancel-button-on-osascript-in-a-bash-script
# licensed under cc-wiki with attribution required
# Remainder of script public domain
osascript -e 'tell application "iTerm2" to version' > /dev/null 2>&1 && NAME=iTerm2 || NAME=iTerm
if [[ $NAME = "iTerm" ]]; then
FILE=`osascript -e 'tell application "iTerm" to activate' -e 'tell application "iTerm" to set thefile to choose folder with prompt "Choose a folder to place received files in"' -e "do shell script (\"echo \"&(quoted form of POSIX path of thefile as Unicode text)&\"\")"`
else
FILE=`osascript -e 'tell application "iTerm2" to activate' -e 'tell application "iTerm2" to set thefile to choose folder with prompt "Choose a folder to place received files in"' -e "do shell script (\"echo \"&(quoted form of POSIX path of thefile as Unicode text)&\"\")"`
fi
if [[ $FILE = "" ]]; then
echo Cancelled.
# Send ZModem cancel
echo -e \\x18\\x18\\x18\\x18\\x18
sleep 1
echo
echo \# Cancelled transfer
else
cd "$FILE"
/usr/local/bin/rz -E -e -b
sleep 1
echo
echo
echo \# Sent \-\> $FILE
fivim /usr/local/bin/iterm2-recv-zmodem.sh<br>chmod +x /usr/local/bin/iterm2-recv-zmodem.sh第三步:设置Trigger
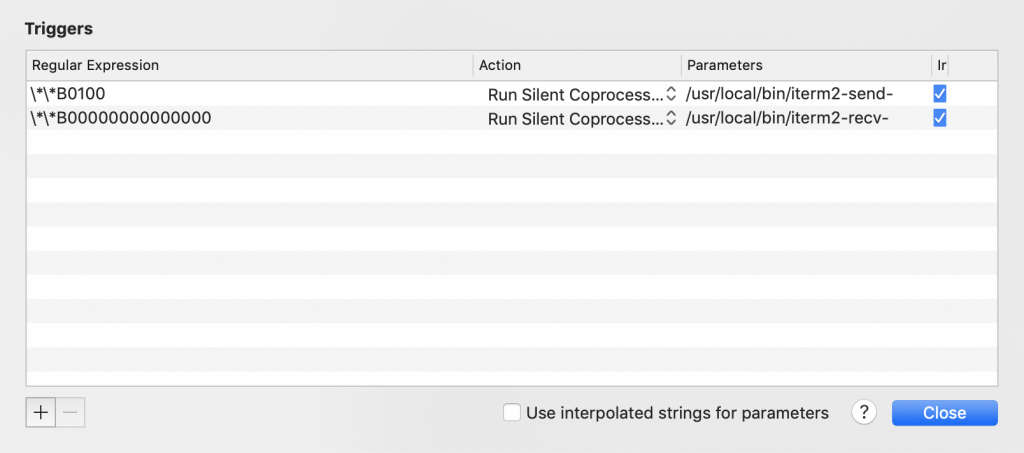
teigger需要设置两个,一个实发送文件的trigger,一个是接收文件的trigger。
打开iterm2->Preferences->Profiles->Advanced->Triggers
点击Edit,点击+号,几个框分别填入下面的内容
Regular expression: \*\*B0100
Action: Run Silent Coprocess
Parameters: /usr/local/bin/iterm2-send-zmodem.sh
Regular expression: \*\*B00000000000000
Action: Run Silent Coprocess
Parameters: /usr/local/bin/iterm2-recv-zmodem.sh最后设置好结果入如下
每次换电脑都需要设置一遍,记录下来备忘。
你可能还喜欢下面这些文章
centos7系统初初始化工作以及网站环境搭建(php7+nginx+mysql)
拿到一台做网站的主机, 我们先要做一些环境初始化的工作, 由于这些工作会有些繁琐,因此记录一下. 后面将这些流程写成一个shell脚本,一次性完成.此次工作流程如下: 安全性设置 额外的目录创建 网站环境搭建安全性设置一般从某云上买的主机, 默认账户是root, 为了不被暴力破解, 我们首先需要设置一个强一点的密码,不过更好的方法是禁用root, 另外创建一个用户来作为日常管理的账户.第一步: 创建一个新的账户,并且能够切换到root权限比如我的用户名叫xiaobai, 添加用户名就是useradd xiaobai设置密码passwd xiaobai之后输入密码,一个新的账户就设定好了.
布隆过滤器(bloom filter)介绍以及php和redis实现布隆过滤器实现方法
引言在介绍布隆过滤器之前我们首先引入几个场景。场景一在一个高并发的计数系统中,如果一个key没有计数,此时我们应该返回0。但是访问的key不存在,相当于每次访问缓存都不起作用了。那么如何避免频繁访问数量为0的key而导致的缓存被击穿?有人说, 将这个key的值置为0存入缓存不就行了吗?这是确实是一种解决方案。当访问一个不存在的key的时候,设置一个带有过期时间的标志,然后放入缓存。不过这样做的缺点也很明显:浪费内存和无法抵御随机key攻击。场景二在一个黑名单系统中,我们需要设置很多黑名单内容。比如一个邮件系统,我们需要设置黑名单用户,当判断垃圾邮件的时候,要怎么去做。比如爬虫系统,我们要记录下
编译步骤gcc 与 g++ 分别是 gnu 的 c & c++ 编译器。gcc/g++ 在执行编译工作的时候,总共需要4步:预处理,生成 .i 的文件将预处理后的文件转换成汇编语言, 生成文件 .s 有汇编变为目标代码(机器代码)生成 .o 的文件连接目标代码, 生成可执行程序 参数详解-x language filename参数含义为指定文件所使用的语言。根据约定,C语言的后缀名称为".c",而 C++ 的后缀名为".cpp"或".cc",但如果你的源代码后缀不约定的那几种,那么需要使用-x参数来指定文件所使用的语言。这个参数对他后面的文件名都起作用。 可以使用的参数吗有下面的这些:
程序员难免要经常画流程图,状态图,时序图等。以前经常用 visio 画,经常为矩形画多大,摆放在哪等问题费脑筋。有时候修改文字后,为了较好的显示效果不得不再去修改图形。今天介绍的工具是如何使用 Sublime + PlantUML 的插件画流程图,状态图,时序图等。这是一种程序员看了就会爱上的画图方式:自然,高效。什么是 PlantUMLPlantUML 是一个画图脚本语言,用它可以快速地画出:时序图流程图用例图状态图组件图简单地讲,我们使用 visio 画图时需要一个一个图去画,但使用 PlantUML 只需要用文字表达出图的内容,然后就可以直接生成图片。看一个最简单的例子:软件安装这些软件
从程序员的角度来看, Shell本身是一种用C语言编写的程序,从用户的角度来看,Shell是用户与Linux操作系统沟通的桥梁。用户既可以输入命令执行,又可以利用 Shell脚本编程,完成更加复杂的操作。在Linux GUI日益完善的今天,在系统管理等领域,Shell编程仍然起着不可忽视的作用。深入地了解和熟练地掌握Shell编程,是每一个Linux用户的必修 功课之一。Linux的Shell种类众多,常见的有:Bourne Shell(/usr/bin/sh或/bin/sh)、Bourne Again Shell(/bin/bash)、C Shell(/usr/bin/csh)、K Shel
C++中,动态内存管理是通过一对运算符来完成:new 和 delete。new操作符在内存中为对象分配空间并返回一个指向该对象的指针,delete接收一个动态对象的指针,销毁该对象,并释放与之相关的内存。手动管理内存看起来只有这两个操作,似乎很轻松,但实际上这是一件非常繁琐的事情,分配了内存但没有释放内存的场景发生的概率太大了!回想一下,你有多少次打开抽屉却没关上,拿出来的护肤品擦完脸之后却忘了放回去,吃完饭却忘了洗碗。类似这种没有收尾的事情我做的太多了。(以上这些都是在实际生活中我爱人批评我的点)我连这种明面上的事情都能忘记收尾,何况分配内存!所以为了世界和平,我放弃了手动管理内存。好在C+
Attention:this blog is a translation of https://www.internalpointers.com/post/c-rvalue-references-and-move-semantics-beginners ,which is posted by @internalpoiners.一、前言在我的前一篇文章里,我解释了右值背后的逻辑。核心的思想就是:在C++中你总会有一些临时的、生命周期较短的值,这些值无论如何你都无法改变。令人惊喜的是,现代C++(通常指C++0x或者更高的版本)引入了右值引用(rvalue reference)的概念:它是一个新的
在使用apidoc之前,我一直使用wiki来写文档,后来发现这种方式更新起来比较痛苦,时间一长甚至就忘记了更新了。一直在寻找能够使用注释直接生成文档的程序。某一天同事推荐了apidoc,发现这正是我想要的工具。apidoc原理apidoc的原理是扫描你的代码文件,提取出注释部分,根据一些规则生成相应的文档。默认的模板久很美观,十分适合作为api文档的生成器。目前apidoc支持的注释基本涵盖了大部分语言的风格了,c,java,php,js,python,perl,lua, Erlang...安装需要使用npm安装,如果没有安装npm,请先去https://www.npmjs.com/下载npm
来熟悉熟悉ftp命令,对于服务器之间的文件传输太有用啦,不会怎么能行呢!先来看看基础的命令,包括了连接,列出列表,下载,上传,断开这最基础的命令,会这些,在使用ftp命令行就毫无压力啦!1. 连接ftp服务器格式:ftp a)在linux命令行下输入:b)服务器询问你用户名和密码,分别输入用户名和相应密码,待认证通过即可。2.列出文件列表以及切换目录这部分其实和linux并无区别,分别是ls,和cd列出目录列表切换当前目录3. 下载文件下载文件通常用get和mget这两条命令。a) get格式:get 将文件从远端主机中传送至本地主机中。如要获取远程服务器上/usr/your/1.htm,则
这是一篇记录树莓派连接wifi的文章。这里我们使用wpa_cli的交互环境来连接无线网,这比直接使用配置要方便得多。注意,wpa_cli需要在root环境下执行终端下面执行: sudo wpa_cli -iwlan0-i参数表示使用哪个网卡,我们需要指定只用wlan0这个网卡。具体可以执行ifconfig看看都有哪些网卡可以使用,如果你的树莓派带有wifi模块,那么一般是wlan0进入交互模式之后,首先需要执行scan命令,该命令能扫描附近的热点。然后输入scan_result列出扫描出来的热点上面扫描出了我的一个手机热点。我们知道了热点的ssid之后就可以连接了,首先增加一个网络连接,执行a
