娱乐之作,大家见笑。^ - ^
本文利用神经网络对股市的预测结果作为分析的对象,打开神经网络的黑箱,找到股市中涨跌的秘密。
量价特征
想要预测股市涨跌,就需要了解在股票上涨和下跌的时候,前一天发生了什么。就好像我们想要预测明天天气的时候,总会想尽办法找到过去几十年甚至几百年下雨的前一段时间都有哪些征兆。预测股票也一样,我们需要想尽一切办法找到某只股票过去几年里面价格上涨的前一天都有哪些特征,越全面越好。
找特征不是一件简单的事情,有效的特征可以为我们增加预测的精准度,而无效的特征会对训练造成干扰。首先从最简单的量价特征开始,即今天的股票的价格变化和交易量变化。
为什么是这两个特征?我的理论依据是市场所有的信息最终都会体现在今天的交易价格和交易量上。这两个特征一定是有效的特征。
为了让预测更加准确,我们加上一个五日均价变化,体现股票最近一段时间的价格变化趋势。
为了尽可能减少可能存在的人为操控股市的影响,我选择了沪深300指数作为分析对象,沪深300整体交易量大,波动小,比较适合分析。
构建一个单层一个节点的网络,如下图,这样训练得到的结果得出来的参数我们会有一个直观的印象。
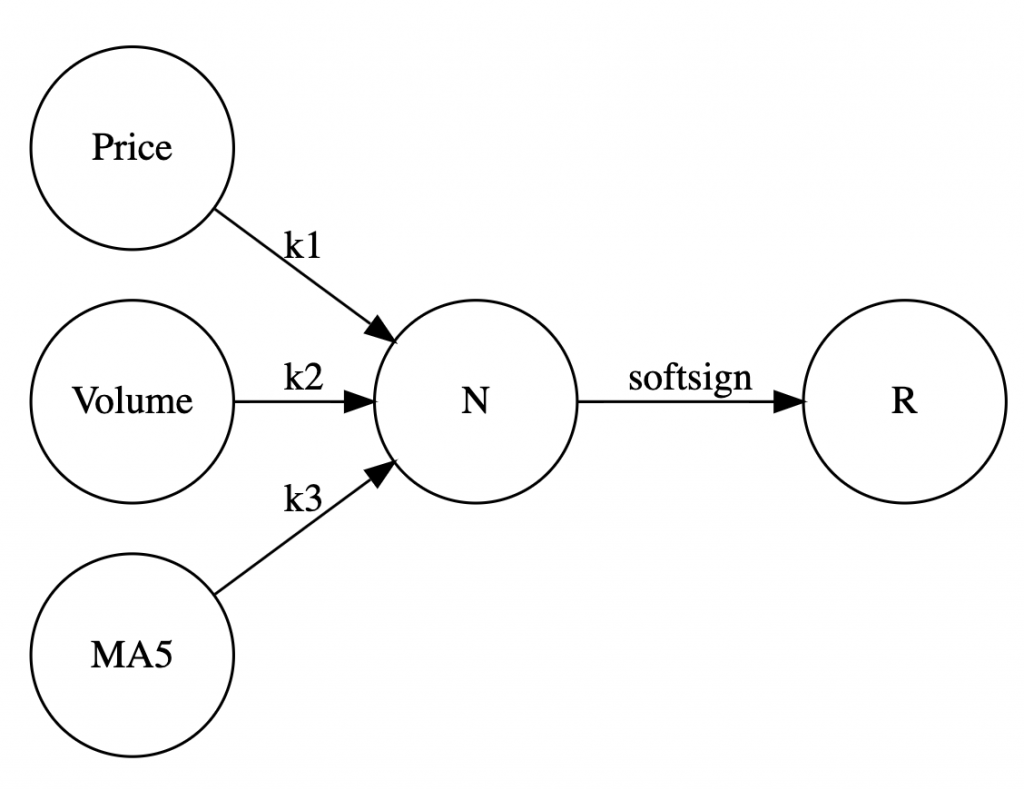
假设R是股票明日的最终涨跌情况,涨为1、跌为0,那么这个网络想要表示的就是价格变化,量变化,五日均价变化分别和未来的涨跌到底是正相关还是负相关。
经过2000次的训练,得到了k1,k2,k3的值,如下:
[[-0.05615718]
[-1.96229 ]
[ 0.30161068]]这个模型的准确率最高只有57%-60%。意味着10次预测,可能只有6次是准确的。虽然准确率不高,但是对于我们揭开股市涨跌的秘密还是有帮助的。
这三个权值就比较有意思,从训练出来的值来看,k1、k2是负数,意味着未来的涨幅和今日量价成负相关,k3是正数,意味着未来的涨幅和今日的量价成正相关。
举个例子,如果今天的量和价都涨,那么乘k1、k2这个负系数,那么整体就往反方向走。如果量和价有一个下跌,那么乘k1、k2这个负系数,整体就往涨的方向上走。
上面的结论可以得出一些推论
推论一:在一个连续上涨的股票中,如果交易量一直在下跌,那么未来可能会继续涨,反之,如果量比较稳定或者量缓慢上涨,那么未来下跌的概率会逐渐增加。
推论二:在一个连续下跌的股票中,如果量一直在涨,那么未来可能还会继续下跌,反之,如果量一直很稳定或者量缓慢下跌,那么未来上涨的概率会逐渐增加。
你可能听到很多专家分析股票,各种线画的比我这个神经网络好看的多,但我认为这些都过于主观,有种一厢情愿的感觉,规律可不会按照你的想法去运行。但上面的这些推论不是我坐在电脑前主观想象出来的,而是根据神经网络训练出来的参数得到的。
结论
如果我们把股票看作是一个商品,那么其实马克思在200多年前就已经告诉我们了:价格是围绕价值波动的,当供不应求,价格就会上涨,当供过于求,价格就会下跌。
在一个稳定的市场环境,股票实际上可以看作是一种商品,当上涨期间,交易量巨大,那就说明供过于求,价格下跌的风险自然就会增加,交易量萎缩,自然就是供不应求,下跌风险自然就会小很多。
定性的分析能让我们把握价格波动的规律,而定量的分析则能够让我们找到涨跌的秘密,k1, k2, k3...这些参数就是股市涨跌的秘密。
你可能还喜欢下面这些文章
上一篇预测股市涨跌的翻车了!毕竟概率在这儿,70%-80%的的概率毕竟不能保证一定是正确的。今天沪深300指数上午上涨,下午开始下跌,最终收跌-0.06%,感觉还好!今天晚上用之前训练好的模型去预测,结果看起来还比较乐观,如图:虽然模型也没能给出明确的涨还是跌,但看起来涨的概率还是比跌的概率稍微大一点点。此外,从我个人的主观感觉来看,明天沪深300上涨的概率也比较大,毕竟前值是下跌的趋势,而最近几天基本跌不下去了。模型说明简单说一下模型里面的数字都是什么意思吧。这些模型是根据过去2年的沪深300的波动特征训练得到的模型,上面的精准度代表预测正确的次数/总次数,比如model_6,精准度为0.7
特征工程是数据分析中最耗时间和精力的一部分工作,它不像算法和模型那样是确定的步骤,更多是工程上的经验和权衡。因此没有统一的方法。这里只是对一些常用的方法做一个总结。本文关注于特征选择部分。后面还有两篇会关注于特征表达和特征预处理。1. 特征的来源在做数据分析的时候,特征的来源一般有两块,一块是业务已经整理好各种特征数据,我们需要去找出适合我们问题需要的特征;另一块是我们从业务特征中自己去寻找高级数据特征。我们就针对这两部分来分别讨论。2. 选择合适的特征我们首先看当业务已经整理好各种特征数据时,我们如何去找出适合我们问题需要的特征,此时特征数可能成百上千,哪些才是我们需要的呢?第一
从融资(融券),融资买入(融券卖出)量,资融(融券)余额看多空博弈
股票市场,除了使用自有资金买卖之外,还可以使用融资和融券的方式去买卖股票。融资融资,表示用户看好这只股票,认为会上涨,不惜借钱买入股票,等待上涨之后卖出之后,偿还之前的借款。举个例子,比如股票10元1股,借10000元可以买入1000股,那么当股票按照期望上涨到11元之后,再卖出就能卖到11000,偿还10000之后盈利1000。融券融券,表示用户不看好这只股票,认为会下跌,不惜借股票卖出换钱,等股票下跌之后再买入相同的股票偿还。举个例子,比如股票10元1股,借1000股之后卖出,当股票按照预期下跌到9元的时候,再买入1000股,只需要花9000,偿还1000股之后,手中盈利1000元。多头和
最近开始研究股票了,自己一个一个的去看,几千支股票完全看不过来啊,想着自己写一个程序,让程序来看股票吧!股票接口首先我们需要得到所有的股票代码,好在已经有网页帮我们列出了所有的股票名称和代码,地址是:http://quote.eastmoney.com/stocklist.html通过这个页面,就可以抓取了。抓取之后我们就可以存入mysql中,每一个股票可以存一张表,而每一张表中则可以存入股票的动态数据。这里我们只能获取到一些最简单的数据,一些更加详细的数据还需要获取,这里需要使用一个腾讯财经的接口http://qt.gtimg.cn/q=sz000858该接口为获取五粮液的股票数据,返回结果
在一个下跌的趋势中,锤子线的出现一般是看涨的,看到锤子线,意味着该买入了。但是一定要记住,锤子线的出现只是表示未来几天内可能会有涨。锤子线的特征1.实体很短,下影线很长,超过实体的两倍以上,无上影线或者上影线很短2.出现在连续的跌势之后3.锤子线的颜色任意证实看涨信号前面说过,锤子线看涨是一个有概率的问题,那么就需要提高这个概率才能让买入不会亏损。这就需要根据锤子线出现的第二天来证实了,如果在锤子线的第二天出现一根阳线,那么这个锤子线的看涨意义就又多了一些。但是这个证实信号太弱了,经过统计发现,未证实的锤子线之后7天内上涨的概率只有40%,通过第二天阳线来证实的锤子线第二天上涨的概率有60%,
一、问题背景随着深度学习的广泛应用,在搜索引擎/推荐系统/机器视觉等业务系统中,越来越多的深度学习模型部署到线上服务。机器学习模型在离线训练时,一般要将输入的数据做特征工程预处理,再输入模型在 TensorFlow PyTorch 等框架上做训练。1.常见的特征工程逻辑常见的特征工程逻辑有: 分箱/分桶 离散化 log/exp 对数/幂等 math numpy 常见数学运算 特征缩放/归一化/截断 交叉特征生成 分词匹配程度计算 字符串分隔匹配判断 tong 缺省值填充等 数据平滑 onehot 编码,hash 编码等这些特征工程代码,当然一般使用深度学习最主要的语言 pyt
“万事万物都有一个模式,它是我们宇宙的一部分。它具有对称、简洁和优雅——这些品质你总能在真正的艺术家的作品中找到。你可以在季节的更替中、在沿着山脊的沙迹中、在杂酚油灌木的树枝丛中或其叶子的图案中找到它。我们试图在我们的生活和社会中复制这些模式,寻找令人舒适的节奏、舞蹈和形式。然而,在寻找终极完美的过程中也可能会遇到危险。显然,最终的模式有其自身的固定性。在如此完美的情况下,一切事物都走向死亡。” ~ 沙丘 (1965)我发现Embedding(中文翻译为嵌入,但不好理解,因此后续直接使用原术语Emdedding表示)的概念是机器学习中最迷人的想法之一。如果您曾经使用过 Siri、Google
这篇文章是漫话中文分词算法的续篇。在这里,我们将紧接着上一篇文章的内容继续探讨下去:如果计算机可以对一句话进行自动分词,它还能进一步整理句子的结构,甚至理解句子的意思吗?这两篇文章的关系十分紧密,因此,我把前一篇文章改名为了《漫话中文自动分词和语义识别(上)》,这篇文章自然就是它的下篇。我已经在很多不同的地方做过与这个话题有关的演讲了,在这里我想把它们写下来,和更多的人一同分享。什么叫做句法结构呢?让我们来看一些例子。“白天鹅在水中游”,这句话是有歧义的,它可能指的是“白天有一只鹅在水中游”,也可能指的是“有一只白天鹅在水中游”。不同的分词方案,产生了不同的意义。有没有什么句子,它的分词方案是
作为代码中,第一个看到的,极有可能就是define这个东西,称为宏!(define是可以出现在任何地方的,但是我们一般把这个写到最开始)然而,很多时候,初学者有时候可能看不懂她,因此,我的c语言学习的第一篇就写这个啦。define基本用法,简单定义最浅显的,define能用一个有含义的字符来替代一些数字,比如#define PI 3.141592654这样,假如以后要计算圆的周长或者面积,就可以用PI这个字符而不用写3.141592654啦。比如#define PI 3.141592654#include "stdio.h"int main(){ int r = 3; float
作为一个博客系统,wordpress在易用性和可扩展性上都非常出色。后题用户体验是非友好,插件众多。然而由于定位的问题,wordpress无法支撑大量文章。当文章数量达到上万的时候,有些主题的前台可能会非常卡。当文章数量达到数十万的时候,wordpress后台可能会特别卡。更何况大部分插件并没有在性能上下功夫,插件越多,wordpress越卡。那么有没有什么方案能让wordpress支撑大量文章?十万,百万,甚至更多?支撑百万数据并不是存入一百万文章就可以了。实际上百万文章对mysql来说毫无压力。在mysql中,百万文章仅仅是百万条记录而已。导致缓慢的是mysql的查询。对于百万条记录的数据
赞赏 微信赞赏
微信赞赏 支付宝赞赏
支付宝赞赏

