未来项目可能要上memcache集群,memcache集群的key分配完全在客户端完成,服务端不做任何处理,这里对key进行分配节点的最优方式就是使用一致性哈希。
记得以前用mysql进行分库分表的时候,通常会用一个求余作为哈希函数,这样一些id就能对应相应的表了。不过使用mysql的时候,我们不需要考虑这些节点失效问题,以及节点增加或者减少的问题(在此之前应该做好足够的计划和准备),但是对于缓存,通常就比较宽松了,允许节点失效问题,但是普通的hash分配在节点失效之后,大部分的缓存位置都改变了,这显然个灾难,这个时候就要考虑一致性hash了,在增加或者删除节点,只有小部分的key会受影响。
一致性哈希的步骤
- 将几个节点(也就是服务器,随便你怎么命名)通过一个hash函数(比如crc32)分别计算出它们的hash值,比如1000,4000,8000,6000,并且排好序,也就是1000,4000,6000,8000
- 将key也通过一个hash函数计算出它的hash值,比如1500
- 将这个key的hash于节点的hash逐一比较,当这个key的hash小于节点的hash,那么这个节点就是这个key所要储存的节点,如果没有找到,那就存到第一个节点。
ok,就这么简单,其实就是一个区间的问题,服务器节点形成一个区间,然后key节点落在哪个区间,就分配到哪个节点。ok,我想还是这些高大上的介绍看起来更舒服一点,不过一开始就看这个,我都嫌啰嗦。明明几句简短的话就能概括,非要一上来就一堆的balabala
![]()
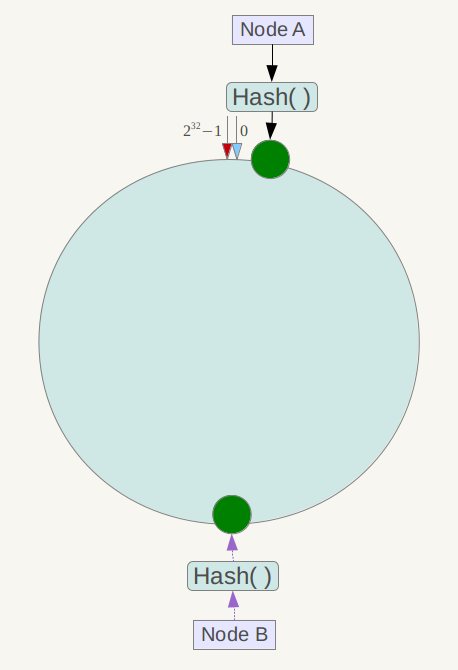
一致性哈希算法(Consistent Hashing)最早在论文《Consistent Hashing and Random Trees: Distributed Caching Protocols for Relieving Hot Spots on the World Wide Web》中被提出。简单来说,一致性哈希将整个哈希值空间组织成一个虚拟的圆环,如假设某哈希函数H的值空间为0-2^32-1(即哈希值是一个32位无符号整形),整个哈希空间环如下:
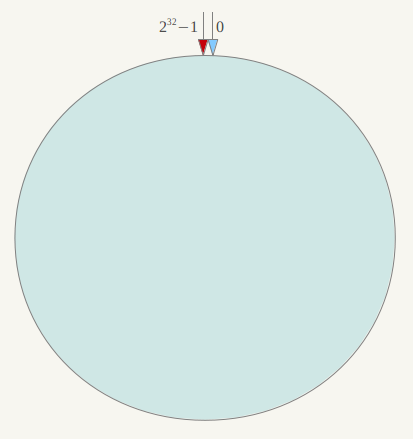
整个空间按顺时针方向组织。0和232-1在零点中方向重合。
下一步将各个服务器使用Hash进行一个哈希,具体可以选择服务器的ip或主机名作为关键字进行哈希,这样每台机器就能确定其在哈希环上的位置,这里假设将上文中四台服务器使用ip地址哈希后在环空间的位置如下:
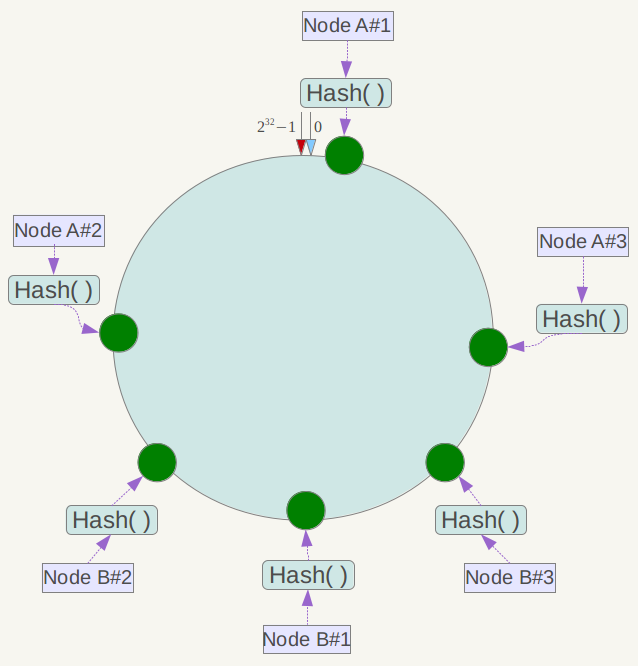
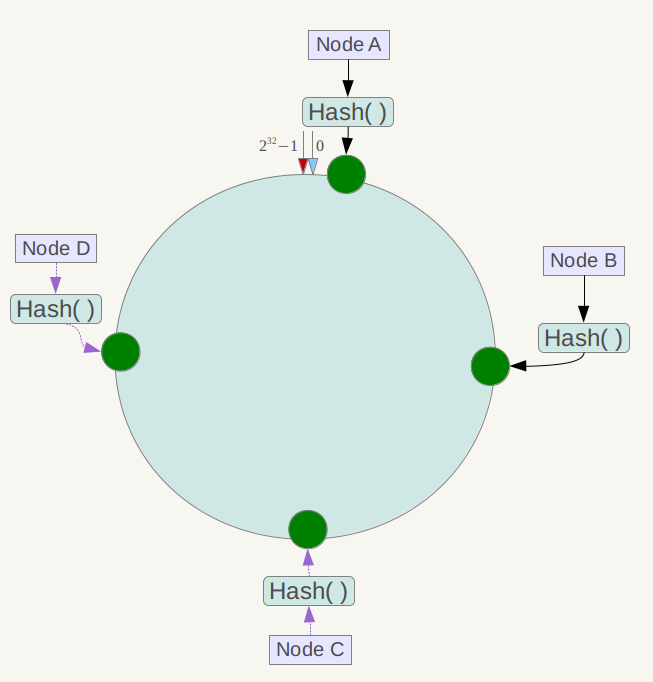
接下来使用如下算法定位数据访问到相应服务器:将数据key使用相同的函数Hash计算出哈希值,并确定此数据在环上的位置,从此位置沿环顺时针“行走”,第一台遇到的服务器就是其应该定位到的服务器。
例如我们有Object A、Object B、Object C、Object D四个数据对象,经过哈希计算后,在环空间上的位置如下:
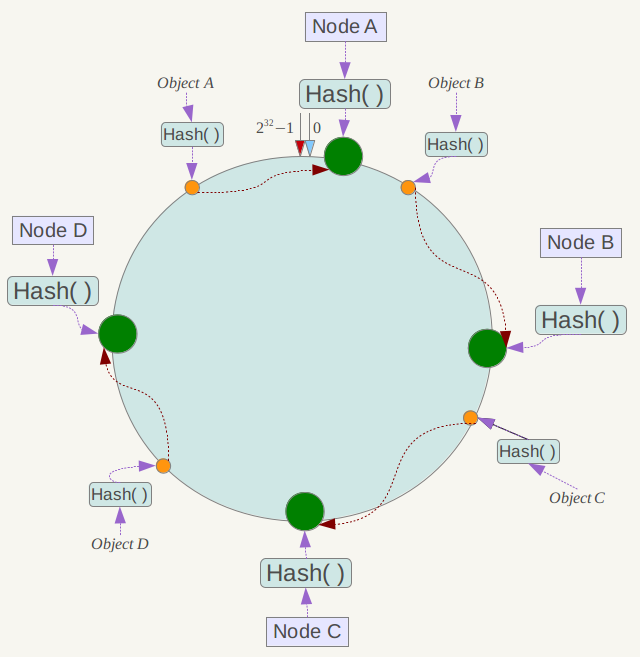
根据一致性哈希算法,数据A会被定为到Node A上,B被定为到Node B上,C被定为到Node C上,D被定为到Node D上。
下面分析一致性哈希算法的容错性和可扩展性。现假设Node C不幸宕机,可以看到此时对象A、B、D不会受到影响,只有C对象被重定位到Node D。一般的,在一致性哈希算法中,如果一台服务器不可用,则受影响的数据仅仅是此服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务 器)之间数据,其它不会受到影响。
下面考虑另外一种情况,如果在系统中增加一台服务器Node X,如下图所示:
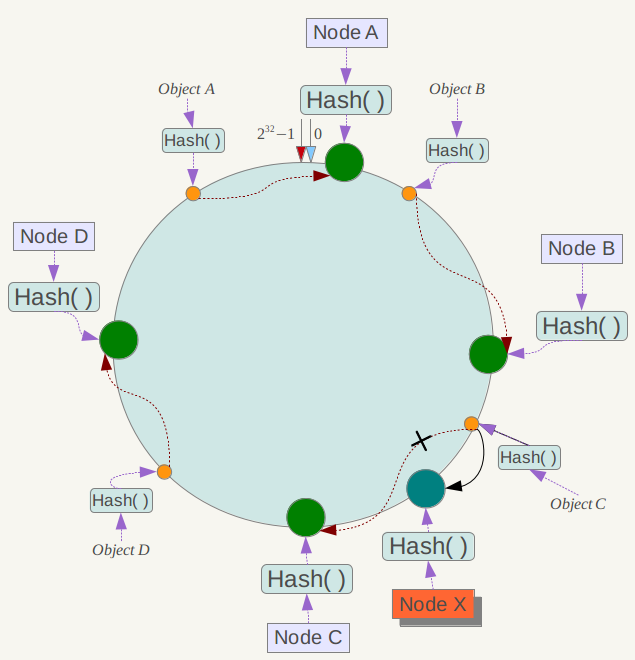
此时对象Object A、B、D不受影响,只有对象C需要重定位到新的Node X 。一般的,在一致性哈希算法中,如果增加一台服务器,则受影响的数据仅仅是新服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器) 之间数据,其它数据也不会受到影响。
综上所述,一致性哈希算法对于节点的增减都只需重定位环空间中的一小部分数据,具有较好的容错性和可扩展性。
另外,一致性哈希算法在服务节点太少时,容易因为节点分部不均匀而造成数据倾斜问题。例如系统中只有两台服务器,其环分布如下,
此时必然造成大量数据集中到Node A上,而只有极少量会定位到Node B上。为了解决这种数据倾斜问题,一致性哈希算法引入了虚拟节点机制,即对每一个服务节点计算多个哈希,每个计算结果位置都放置一个此服务节点,称为虚拟 节点。具体做法可以在服务器ip或主机名的后面增加编号来实现。例如上面的情况,可以为每台服务器计算三个虚拟节点,于是可以分别计算 “Node A#1”、“Node A#2”、“Node A#3”、“Node B#1”、“Node B#2”、“Node B#3”的哈希值,于是形成六个虚拟节点:
同时数据定位算法不变,只是多了一步虚拟节点到实际节点的映射,例如定位到“Node A#1”、“Node A#2”、“Node A#3”三个虚拟节点的数据均定位到Node A上。这样就解决了服务节点少时数据倾斜的问题。在实际应用中,通常将虚拟节点数设置为32甚至更大,因此即使很少的服务节点也能做到相对均匀的数据分布。
一致性hash的php实现
实现方式也很简单,就直接上代码了
<?php
class ConsistentHash
{
/**
* nodes array
* @var array
*/
protected $nodes = array();
/**
* virtual nodes
* @var array
*/
protected $virtualNodes = array();
/**
* sort
* @var boolean
*/
protected $isSort = false;
/**
* virtual nodes num
* @var integer
*/
protected $virtualNodesNum = 10;
public function __construct()
{
}
public function setVirtualNum($num)
{
$this->virtualNodesNum = $num;
}
public function addNode($node)
{
$this->nodes[] = $node;
for( $i=0; $i<$this->virtualNodesNum; $i++ ){
$virtualHash = sprintf("%u",crc32($node.$i));
$this->virtualNodes[$virtualHash] = $node;
}
return true;
}
public function addNodes($nodes)
{
foreach($nodes as $node){
$this->addNode($node);
}
}
public function getNode($key)
{
if( !$this->isSort ){
ksort($this->virtualNodes);
$this->isSort = true;
}
$hashKey = sprintf("%u",crc32($key));
foreach($this->virtualNodes as $hashNode=>$node){
if( $hashKey < $hashNode ){
return $node;
}
}
return $this->nodes[0];
}
}
代码托管在github : https://github.com/cmhc/consistanthash
你可能还喜欢下面这些文章
树树是一种层次关系,在日常生活非常常见,比如社会关系,亲缘关系,文件管理。一棵树是一些节点的集合,这个集合可以是空集,若非空,则一棵树由称作为根的节点r以及0个或者多个非空的(子)树组成,这些子树中的每一棵都是被来自根r的一条有向的边所连接。一种数据结构需要包含一些操作,树这种数据结构有增加,删除,查找,修改。节点节点的度:节点子树的个数。叶子节点:没有儿子的节点,也就是度为0的节点。节点的层次:规定跟节点在1层,其他节点的层次为父节点的层次加1。节点的高:节点的高为从这个节点到叶子的最长路径,所有树叶的高都是0。节点的深度:从跟节点到该节点的唯一路径长,根的深度为0。节点定义typedef
在php中,没有多线程让编程变得简单。但在一些需要并发提升性能的场景下,显得有些无能为力,比如发起一些http请求。但好在curl扩展可以让我们“并发”去请求网络资源。利用这个特点,我们能做很多有趣的事情。最基础的,并发请求网络资源,提升处理速度。并发访问代码<?phpclass ConcurrencyHTTP { private $_requests; private $_callbacks; private $_currentIndex = 0; public function get($url, $header = array(), $timeout = 3
来熟悉熟悉ftp命令,对于服务器之间的文件传输太有用啦,不会怎么能行呢!先来看看基础的命令,包括了连接,列出列表,下载,上传,断开这最基础的命令,会这些,在使用ftp命令行就毫无压力啦!1. 连接ftp服务器格式:ftp a)在linux命令行下输入:b)服务器询问你用户名和密码,分别输入用户名和相应密码,待认证通过即可。2.列出文件列表以及切换目录这部分其实和linux并无区别,分别是ls,和cd列出目录列表切换当前目录3. 下载文件下载文件通常用get和mget这两条命令。a) get格式:get 将文件从远端主机中传送至本地主机中。如要获取远程服务器上/usr/your/1.htm,则
介绍一款工具,memcacheadmin,使用php制作的memcached管理监控工具
MemAdmin是一款可视化的Memcached管理与监控工具,使用PHP开发,体积小,操作简单。主要功能: 服务器参数监控:STATS、SETTINGS、ITEMS、SLABS、SIZES实时刷新 服务器性能监控:GET、DELETE、INCR、DECR、CAS等常用操作命中率实时监控 支持数据遍历,方便对存储内容进行监视 支持条件查询,筛选出满足条件的KEY或VALUE 数组、JSON等序列化字符反序列显示 兼容memcache协议的其他服务,如Tokyo Tyrant (遍历功能除外) 支持服务器连接池,多服务器管理切换方便简洁guthub地址:https://github.com/ju
布隆过滤器(bloom filter)介绍以及php和redis实现布隆过滤器实现方法
引言在介绍布隆过滤器之前我们首先引入几个场景。场景一在一个高并发的计数系统中,如果一个key没有计数,此时我们应该返回0。但是访问的key不存在,相当于每次访问缓存都不起作用了。那么如何避免频繁访问数量为0的key而导致的缓存被击穿?有人说, 将这个key的值置为0存入缓存不就行了吗?这是确实是一种解决方案。当访问一个不存在的key的时候,设置一个带有过期时间的标志,然后放入缓存。不过这样做的缺点也很明显:浪费内存和无法抵御随机key攻击。场景二在一个黑名单系统中,我们需要设置很多黑名单内容。比如一个邮件系统,我们需要设置黑名单用户,当判断垃圾邮件的时候,要怎么去做。比如爬虫系统,我们要记录下
程序员难免要经常画流程图,状态图,时序图等。以前经常用 visio 画,经常为矩形画多大,摆放在哪等问题费脑筋。有时候修改文字后,为了较好的显示效果不得不再去修改图形。今天介绍的工具是如何使用 Sublime + PlantUML 的插件画流程图,状态图,时序图等。这是一种程序员看了就会爱上的画图方式:自然,高效。什么是 PlantUMLPlantUML 是一个画图脚本语言,用它可以快速地画出:时序图流程图用例图状态图组件图简单地讲,我们使用 visio 画图时需要一个一个图去画,但使用 PlantUML 只需要用文字表达出图的内容,然后就可以直接生成图片。看一个最简单的例子:软件安装这些软件
当我们在谈到cgi的时候,我们在讨论什么最早的Web服务器简单地响应浏览器发来的HTTP请求,并将存储在服务器上的HTML文件返回给浏览器,也就是静态html。事物总是不 断发展,网站也越来越复杂,所以出现动态技术。但是服务器并不能直接运行 php,asp这样的文件,自己不能做,外包给别人吧,但是要与第三做个约定,我给你什么,然后你给我什么,就是握把请求参数发送给你,然后我接收你的处 理结果给客户端。那这个约定就是 common gateway interface,简称cgi。这个协议可以用vb,c,php,python 来实现。cgi只是接口协议,根本不是什么语言。下面图可以看到流程WEB服
在打算搭建memcache集群的时候,使用了crc3算法来对key进行hash,然而发现该算法性能比较低,于是寻找一个高性能,低碰撞的hash算,很高兴有前人已经为我们发明了这种算法——murmur。MurmurHash算法:高运算性能,低碰撞率,由Austin Appleby创建于2008年,现已应用到Hadoop、libstdc++、nginx、libmemcached等开源系统。2011年 Appleby被Google雇佣,随后Google推出其变种的CityHash算法。MurmurHash算法,自称超级快的hash算法,是FNV的4-5倍。官方数据如下:OneAtATime – 35
机器搬家之后,之前一直稳定的PHP多进程程序子进程突然异常退出,但是退出的不是很频繁,查看进程日志并也没有发现有什么导致退出的,问题比较诡异。于是开启了一段问题排查之路。首先查看内核日志,使用dmesg,拉到最后发现有一些这样的错误,看来确实是崩溃了。 php: segfault at 7f6443ee18c8 ip 00007f6443ee18c8 sp 00007fff4d4ba818 error 15 in libc-2.17.so php: segfault at 0 ip 000000000075919d sp 00007fff0c6e0578 error 4 in php trap
记得第一次了解中文分词算法是在 Google 黑板报 上看到的,当初看到那个算法时我彻底被震撼住了,想不到一个看似不可能完成的任务竟然有如此神奇巧妙的算法。最近在詹卫东老师的《中文信息处理导论》课上再次学到中文分词算法,才知道这并不是中文分词算法研究的全部,前前后后还有很多故事可讲。在没有建立统计语言模型时,人们还在语言学的角度对自动分词进行研究,期间诞生了很多有意思的理论。中文分词的主要困难在于分词歧义。“结婚的和尚未结婚的”,应该分成“结婚/的/和/尚未/结婚/的”,还是“结婚/的/和尚/未/结婚/的”?人来判断很容易,要交给计算机来处理就麻烦了。问题的关键就是,“和尚未”里的“和尚”也是
赞赏 微信赞赏
微信赞赏 支付宝赞赏
支付宝赞赏

