最近在写hadoop的streaming任务,在输出的时候用了std::endl,就像下面这样:
os << "content" << std::endl运行后发现程序跑的比python还慢,令人费解。我入门C++的时候,输出hello world也是这样写的,有什么问题?
于是查了一下std::endl,发现问题挺大。std::endl解释如下:
Inserts a new-line character and flushes the stream.
Its behavior is equivalent to calling os.put('\n') (or os.put(os.widen('\n')) for character types other than char), and then os.flush().也就是说每次执行到std::endl的时候都会将缓冲区的内容写入到输出的对象中,这样一来速度慢也就不足为奇。
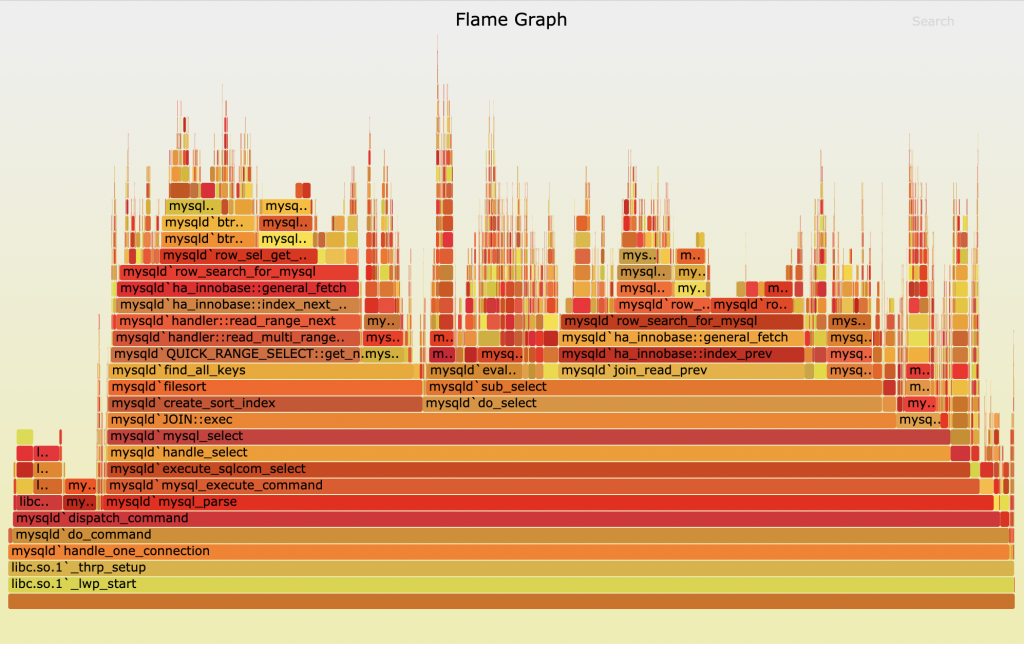
性能测试
#include "timer.h"
#include <fstream>
#include <iostream>
int main() {
{
Timer timer;
fstream fs("./with_endl.txt", std::fstream::out);
for (int i = 0; i<100000; i++) {
fs << "test" << std::endl;
}
std::cout << "with endl:" << timer.elapsed() << "ms \n";
}
{
Timer timer;
fstream fs("./without_endl.txt", std::fstream::out);
for (int i = 0; i<100000; i++) {
fs << "test" << "\n";
}
std::cout << "without endl:" <<timer.elapsed() << "ms \n";
}
}with endl:397ms
without endl:18ms 不加std::endl性能高出20倍。如果程序的逻辑十分简单,那么输出字符串的时候最好用"\n"代替加std::endl
你可能还喜欢下面这些文章
在使用php的时候,我很少用到print这个函数,哦,不对,这是一个语言结构,而并非日函数!看一段代码
bash 4.1.2 版本增加了map数据结构。map是一种常用的数据结构,通过map可以将key映射到一个value。使用方法map在使用之前需要先声明,声明的方式如下map需要先声明再使用。参数-A表示声明的变量是一个map。需要注意的是这里的A是大写的字母A。赋值操作map的赋值有两种方式,一种是直接给map赋值,如下:另一种是使用下标给map添加key-value对输出所有的key在文中最开始提到map的使用需要先声明,在没有声明的情况下此处会输出一个0,如下图:输出所有value输出map长度遍历,根据key找到对应的value遍历所有的key遍历所有的value问题FAQQ:为什么
在C++中,字符串拼接可以使用多种方法,下面是一些常用的方法:使用 运算符C++中的 类型支持 运算符来进行字符串拼接。使用 成员函数 类提供了 成员函数,它可以用来拼接字符串。使用 运算符 也支持 运算符来进行字符串拼接。使用 C 风格的字符串拼接虽然不推荐使用C风格的字符串拼接(因为它可能会导致缓冲区溢出),但你还是可以在C++中这样做。在这种情况下,你需要确保目标缓冲区有足够的空间来存储拼接后的字符串。在这个例子中, 函数被用来拼接两个C风格的字符串。注意,在使用 之前,我们检查了 是否有足够的空间来存储拼接后的字符串,以防止缓冲区溢出。使用 对于更复杂的字符串拼接,特
每次启动程序都要敲一堆命令,终止程序都要ps+grep找到程序pid然后kill,太麻烦了!花了点时间写了个程序启动停止脚本,如下:只需要配置一个BIN变量即可实现程序的启动和停止,十分简单。
在Python中, 是字符串(str)对象的一个方法,用于从字符串的末尾(右侧)开始分割字符串。这个方法与 方法相似,但方向相反。 方法接受一个分隔符(默认为所有空白字符)和一个最大分割次数作为参数,并返回分割后的子字符串列表。下面是 方法的基本语法::分隔符,用于指定如何分割字符串。如果不指定分隔符,则默认为所有的空白字符(包括空格、换行符 、制表符 等)。:可选参数,指定最大分割次数。如果指定了 ,则分割不会超过这个指定的次数,并且结果列表的长度最多为 。如果 参数被省略或者为 -1,则分割会进行到字符串的末尾。下面是一些使用 方法的例子:注意:如果 参数为空字符串 ,则 会
在 Python 中, 是一个列表或字符串的切片操作,用于获取从开始到倒数第二个元素(或字符)的子序列。对于列表:对于字符串:这里的关键是切片操作中的 后面的 ,它表示从末尾开始计数的第一个元素之前的所有元素。具体来说, 是最后一个元素, 是倒数第二个元素,依此类推。因此, 或 都会返回从开始到倒数第二个元素的子序列。
一、问题背景随着深度学习的广泛应用,在搜索引擎/推荐系统/机器视觉等业务系统中,越来越多的深度学习模型部署到线上服务。机器学习模型在离线训练时,一般要将输入的数据做特征工程预处理,再输入模型在 TensorFlow PyTorch 等框架上做训练。1.常见的特征工程逻辑常见的特征工程逻辑有: 分箱/分桶 离散化 log/exp 对数/幂等 math numpy 常见数学运算 特征缩放/归一化/截断 交叉特征生成 分词匹配程度计算 字符串分隔匹配判断 tong 缺省值填充等 数据平滑 onehot 编码,hash 编码等这些特征工程代码,当然一般使用深度学习最主要的语言 pyt
根据如何学习一门新的语言这篇文章的指导,现在的步骤就是学习这门语言的流程控制了。通常来讲,流程控制有顺序,选择,循环这几种。python也不例外,也有这三种流程控制。下面的一一学习。顺序顺序语句很简单,从上往下依次顺序执行。如:a = 1b = 2print(a+b)上面的语句就是顺序执行的语句。选择选择通常使用if和switch,但python中只有if这一个选择语句。语法是:if 满足条件1: 语句1elif 不满足条件1满足1条件2 语句2else 都不满足 语句3比如用一个实际的例子a = 1b = 2if a > b: print('a>b')el
写入安全(Write Concern)是一种由客户端设置的,用于控制写入安全级别的机制,通过使用写入安全机制可以提高数据的可靠性。MongoDB提供四种写入级别,分别是: (Unacknowledged)非确认式写入 (Acknowledged)确认式写入 (Journaled)日志写入 (Replica Acknowledged)复制集确认式写入1. 非确认式写入2. 确认式写入 3. journal日志写入64位机器上,MongoDB 2.0以上版本默认情况下是开启journaljournal文件位于journal目录中,只能以追加方式添加数据,文件名以j._开头数据库正
在Go语言中做单元测试和性能测试是一件非常容易的事情——Go自带了测试工具包,testing包。通常,测试代码和功能代码在同一个包中,测试代码以“_test”结尾。测试有两种类型,一种是单元测试(UnitTest),一种是性能测试(Benchmark)。接下来将会介绍一下如何写这两种测试。单元测试首先创建一个测试文件,命名foo_test.go(提示: 以test结尾)接下来是创建测试函数,Test_Foo(提示:测试函数以Test开头,传入*testing.T指针),代码如下:func Test_Foo(t *testing.T) {}这里什么也没做,只是创建了一个空的测试函数,但确实是能运