Attention:this blog is a translation of https://www.internalpointers.com/post/understanding-meaning-lvalues-and-rvalues-c ,which is posted by @internalpoiners.
一、前言
一直以来,我都对C++中左值(lvalue)和右值(lvalue)的概念模糊不清。我认为是时候好好理解他们了,因为这些概念随着C++语言的进化变得越来越重要。
二、左值和右值——一个友好的定义
首先,让我们避开那些正式的定义。在C++中,一个左值是指向一个指定内存的东西。另一方面,右值就是不指向任何地方的东西。通常来说,右值是暂时和短命的,而左值则活的很久,因为他们以变量的形式(variable)存在。我们可以将左值看作为容器(container)而将右值看做容器中的事物。如果容器消失了,容器中的事物也就自然就无法存在了。
让我们现在来看一些例子:
int x = 666; //ok
在这里,666是一个右值。一个数字(从技术角度来说他是一个字面常量(literal constant))没有指定的内存地址,当然在程序运行时一些临时的寄存器除外。在该例中,666被赋值(assign)给x,x是一个变量。一个变量有着具体(specific)的内存位置,所以他是一个左值。C++中声明一个赋值(assignment)需要一个左值作为它的左操作数(left operand):这完全合法。
对于左值x,你可以做像这样的操作:
int* y = &x; //ok
在这里我通过取地址操作符&获取了x的内存地址并且把它放进了y。&操作符需要一个左值并且产生了一个右值,这也是另一个完全合法的操作:在赋值操作符的左边我们有一个左值(一个变量),在右边我们使用取地址操作符产生的右值。
然而,我们不能这样写:
int y;
666 = y; //error!
可能上面的结论是显而易见的,但是从技术上来说是因为666是一个字面常量也就是一个右值,它没有一个具体的内存位置(memory location),所以我们会把y分配到一个不存在的地方。
下面是GCC给出的变异错误提示:
error: lvalue required as left operand of assignment
赋值的左操作数需要一个左值,这里我们使用了一个右值666。
我们也不能这样做:
int* y = &666;// error~
GCC给出了以下错误提示:
error: lvalue required as unary '&' operand`
&操作符需要一个左值作为操作数,因为只有一个左值才拥有地址。
三、返回左值和右值的函数
我们知道一个赋值的左操作数必须是一个左值,因此下面的这个函数肯定会抛出错误:lvalue required as left operand of assignment
int setValue()
{
return 6;
}
// ... somewhere in main() ...
setValue() = 3; // error!
错误原因很清楚:setValue()返回了一个右值(一个临时值6),他不能作为一个赋值的左操作数。现在,我们看看如果函数返回一个左值,这样的赋值会发生什么变化。看下面的代码片段(snippet):
int global = 100;
int& setGlobal()
{
return global;
}
// ... somewhere in main() ...
setGlobal() = 400; // OK
该程序可以运行,因为在这里setGlobal()返回一个引用(reference),跟之前的setValue()不同。一个引用是指向一个已经存在的内存位置(global变量)的东西,因此它是一个左值,所以它能被赋值。注意这里的&:它不是取地址操作符,他定义了返回的类型(一个引用)。
可以从函数返回左值看上去有些隐晦,它在你做一些进阶的编程例如实现一些操作符的重载(implementing overload operators)时会很有作用,这些知识会在未来的章节中讲述。
四、左值到右值的转换
一个左值可以被转换(convert)为右值,这完全合法且经常发生。让我们先用+操作符作为一个例子,根据C++的规范(specification),它使用两个右值作为参数并返回一个右值(译者按:可以将操作符理解为一个函数)。
让我们看下面的代码片段:
int x = 1;
int y = 3;
int z = x + y; // ok
等一下,x和y是左值,但是加法操作符需要右值作为参数:发生了什么?答案很简单:x和y经历了一个隐式(implicit)的左值到右值(lvalue-to-rvalue)的转换。许多其他的操作符也有同样的转换——减法、加法、除法等等。
五、左值引用
相反呢?一个右值可以被转化为左值吗?不可以,它不是技术所限,而是C++编程语言就是那样设计的。
在C++中,当你做这样的事:
int y = 10;
int& yref = y;
yref++; // y is now 11
这里将yref声明为类型int&:一个对y的引用,它被称作左值引用(lvalue reference)。现在你可以开心地通过该引用改变y的值了。
我们知道,一个引用必须只想一个具体的内存位置中的一个已经存在的对象,即一个左值。这里y确实存在,所以代码运行完美。
现在,如果我缩短整个过程,尝试将10直接赋值给我的引用,并且没有任何对象持有该引用,将会发生什么?
int& yref = 10; // will it work?
在右边我们有一个临时值,一个需要被存储在一个左值中的右值。在左边我们有一个引用(一个左值),他应该指向一个已经存在的对象。但是10 是一个数字常量(numeric constant),也就是一个左值,将它赋给引用与引用所表述的精神冲突。
如果你仔细想想,那就是被禁止的从右值到左值的转换。一个volitile的数字常量(右值)如果想要被引用,需要先变成一个左值。如果那被允许,你就可以通过它的引用来改变数字常量的值。相当没有意义,不是吗?更重要的是,一旦这些值不再存在这些引用该指向哪里呢?
下面的代码片段同样会发生错误,原因跟刚才的一样:
void fnc(int& x)
{
}
int main()
{
fnc(10); // Nope!
// This works instead:
// int x = 10;
// fnc(x);
}
我将一个临时值10传入了一个需要引用作为参数的函数中,产生了将右值转换为左值的错误。这里有一个解决方法(workaround),创造一个临时的变量来存储右值,然后将变量传入函数中(就像注释中写的那样)。将一个数字传入一个函数确实不太方便。
六、常量左值引用
先看看GCC对于之前两个代码片段给出的错误提示:
error: invalid initialization of non-const reference of type 'int&' from an rvalue of type 'int'
GCC认为引用不是const的,即一个常量。根据C++规范,你可以将一个const的左值绑定到一个右值上,所以下面的代码可以成功运行:
const int& ref = 10; // OK!
当然,下面的也是:
void fnc(const int& x)
{
}
int main()
{
fnc(10); // OK!
}
背后的道理是相当直接的,字面常量10是volatile的并且会很快失效(expire),所以给他一个引用是没什么意义的。如果我们让引用本身变成常量引用,那样的话该引用指向的值就不能被改变了。现在右值被修改的问题被很好地解决了。同样,这不是一个技术限制,而是C ++人员为避免愚蠢麻烦所作的选择。
应用:C++中经常通过常量引用来将值传入函数中,这避免了不必要的临时对象的创建和拷贝。
编译器会为你创建一个隐藏的变量(即一个左值)来存储初始的字面常量,然后将隐藏的变量绑定到你的引用上去。那跟我之前的一组代码片段中手动完成的是一码事,例如:
// the following...
const int& ref = 10;
// ... would translate to:
int __internal_unique_name = 10;
const int& ref = __internal_unique_name;
现在你的引用指向了真实存在的事物(知道它走出作用域外)并且你可以正常使用它,出克改变他指向的值。
const int& ref = 10;
std::cout << ref << "\n"; // OK!
std::cout << ++ref << "\n"; // error: increment of read-only reference ‘ref’
七、结论
理解左值和右值的含义让我弄清楚了几个C++内在的工作方式。C++11进一步推动了右值的限定,引入了右值引用(rvalue reference)和移动(move semantics)的概念。
来源 https://www.jianshu.com/p/94b0221f64a5
你可能还喜欢下面这些文章
C++右值引用和移动
Attention:this blog is a translation of https://www.internalpointers.com/post/c-rvalue-references-and-move-semantics-beginners ,which is posted by @internalpoiners.一、前言在我的前一篇文章里,我解释了右值背后的逻辑。核心的思想就是:在C++中你总会有一些临时的、生命周期较短的值,这些值无论如何你都无法改变。令人惊喜的是,现代C++(通常指C++0x或者更高的版本)引入了右值引用(rvalue reference)的概念:它是一个新的
C++入门:一、变量和数据类型
这是我的C++学习笔记第一篇,同所有的程序语言学习路径一样,首先学习的是变量和数据类型。我的学习路径如下:1. 变量和数据类型2. 流程控制3. 函数声明和调用4. 面向对象5. 标准库这一章,学习的是变量和数据类型,需要了解的有:了解这些,对于变量基本就够了。Hello world在开始之前,先写一个hello world来熟悉一下程序的主要结构以及如何打印一个变量。iostream提供标准输入输出的头文件,程序以main函数问入口,std为标准库的命名空间,“<<” 为输出操作符,std::cout为标准输出,std::endl为结束符,表示将等待输出的内容从内存传送到标准输出
centos7系统初初始化工作以及网站环境搭建(php7+nginx+mysql)
拿到一台做网站的主机, 我们先要做一些环境初始化的工作, 由于这些工作会有些繁琐,因此记录一下. 后面将这些流程写成一个shell脚本,一次性完成.此次工作流程如下: 安全性设置 额外的目录创建 网站环境搭建安全性设置一般从某云上买的主机, 默认账户是root, 为了不被暴力破解, 我们首先需要设置一个强一点的密码,不过更好的方法是禁用root, 另外创建一个用户来作为日常管理的账户.第一步: 创建一个新的账户,并且能够切换到root权限比如我的用户名叫xiaobai, 添加用户名就是useradd xiaobai设置密码passwd xiaobai之后输入密码,一个新的账户就设定好了.
iterm2 使用 rz、sz 的方法
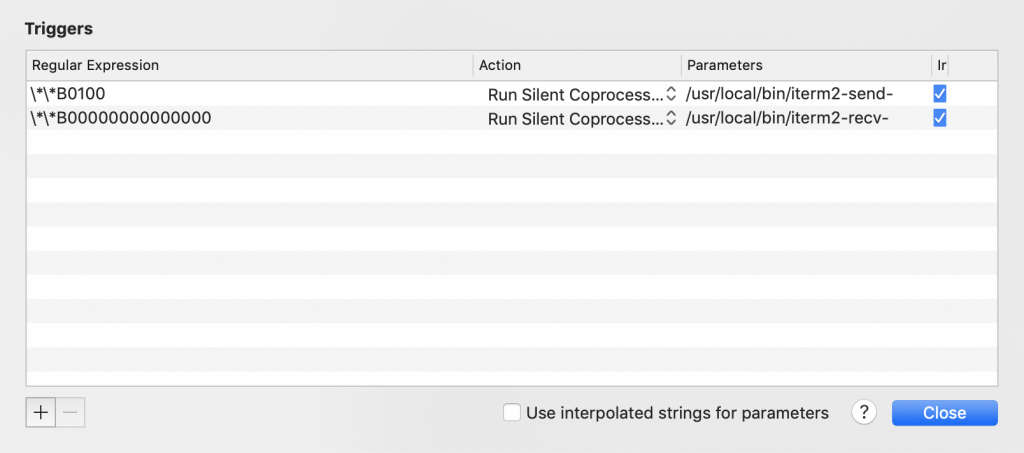
如果没有额外的设置,iterm2 使用 rzsz 的时候会卡在这个时候就需要使用iterm2提供的trigger来实现rzsz的功能。第一步:本机安装rzsz使用rzsz之前本地也需要安装如果没有安装brew,请先安装brew,mac必备的包管理器!第二步:创建发送和接收脚本发送文件的脚本如下,可以复制下面的内容,保存在 /usr/local/bin/iterm2-send-zmodem.sh中。接收文件的脚本如下,同样可以复制保存在/usr/local/bin/iterm2-recv-zmodem.sh第三步:设置Triggerteigger需要设置两个,一个实发送文件的trigger,一个
布隆过滤器(bloom filter)介绍以及php和redis实现布隆过滤器实现方法
引言在介绍布隆过滤器之前我们首先引入几个场景。场景一在一个高并发的计数系统中,如果一个key没有计数,此时我们应该返回0。但是访问的key不存在,相当于每次访问缓存都不起作用了。那么如何避免频繁访问数量为0的key而导致的缓存被击穿?有人说, 将这个key的值置为0存入缓存不就行了吗?这是确实是一种解决方案。当访问一个不存在的key的时候,设置一个带有过期时间的标志,然后放入缓存。不过这样做的缺点也很明显:浪费内存和无法抵御随机key攻击。场景二在一个黑名单系统中,我们需要设置很多黑名单内容。比如一个邮件系统,我们需要设置黑名单用户,当判断垃圾邮件的时候,要怎么去做。比如爬虫系统,我们要记录下
C++入门:三、函数
这是我学习C++的第三篇笔记,函数。我的学习路径是现在学习的是函数的声明、定义、调用等相关知识。函数声明和定义函数的声明包含返回类型,函数名字,0个或者多个形参,无函数体,通常在头文件中对函数进行声明。函数的定义包含返回类型,函数名字,0个或多个形参,以及函数体。比如写一个求阶乘的函数,可以写成下面这样写一些简单的函数大多数语言都差不多,不过可惜每种语言或多或少都有自己的特色,这是比较令人头秃的地方。函数的参数函数可以带有0或多个参数,每个参数都需要声明类型。参数传递可以传值和传引用。如果形参是引用类型,那么它将绑定到对应的实参中,我们成为传引用。否则,将会把实参的值拷贝后赋值给形参,我们成为
C++动态内存管理
C++中,动态内存管理是通过一对运算符来完成:new 和 delete。new操作符在内存中为对象分配空间并返回一个指向该对象的指针,delete接收一个动态对象的指针,销毁该对象,并释放与之相关的内存。手动管理内存看起来只有这两个操作,似乎很轻松,但实际上这是一件非常繁琐的事情,分配了内存但没有释放内存的场景发生的概率太大了!回想一下,你有多少次打开抽屉却没关上,拿出来的护肤品擦完脸之后却忘了放回去,吃完饭却忘了洗碗。类似这种没有收尾的事情我做的太多了。(以上这些都是在实际生活中我爱人批评我的点)我连这种明面上的事情都能忘记收尾,何况分配内存!所以为了世界和平,我放弃了手动管理内存。好在C+
linux shell 入门
从程序员的角度来看, Shell本身是一种用C语言编写的程序,从用户的角度来看,Shell是用户与Linux操作系统沟通的桥梁。用户既可以输入命令执行,又可以利用 Shell脚本编程,完成更加复杂的操作。在Linux GUI日益完善的今天,在系统管理等领域,Shell编程仍然起着不可忽视的作用。深入地了解和熟练地掌握Shell编程,是每一个Linux用户的必修 功课之一。Linux的Shell种类众多,常见的有:Bourne Shell(/usr/bin/sh或/bin/sh)、Bourne Again Shell(/bin/bash)、C Shell(/usr/bin/csh)、K Shel
php的empty,isset,is_null与!
来说说php的empty,isset,is_null 与!,这几个都是if语句中比较常见的判断逻辑。但是有时候用的很纠结,甚至看别人写的程序里面也很纠结。特地梳理梳理,避免踩坑先来定义一些东西<?php$a;$b=0;$c=array();$d='';$e=null;empty,用了会上瘾这是一个用了会上瘾的语言结构!多好,empty可接受的参数是一个变量,任意类型,哪怕是变量不存在,只要变量被boolean转换之后是false(参考:php的boolean都有哪些),那么empty返回的就是false,并且不会出现警告!等价于不过注意的是,empty里面不能使用表达式(在php<
还能这样?把 Python 自动翻译成 C++
一、问题背景随着深度学习的广泛应用,在搜索引擎/推荐系统/机器视觉等业务系统中,越来越多的深度学习模型部署到线上服务。机器学习模型在离线训练时,一般要将输入的数据做特征工程预处理,再输入模型在 TensorFlow PyTorch 等框架上做训练。1.常见的特征工程逻辑常见的特征工程逻辑有: 分箱/分桶 离散化 log/exp 对数/幂等 math numpy 常见数学运算 特征缩放/归一化/截断 交叉特征生成 分词匹配程度计算 字符串分隔匹配判断 tong 缺省值填充等 数据平滑 onehot 编码,hash 编码等这些特征工程代码,当然一般使用深度学习最主要的语言 pyt